A naukri.com initiative
The New Stack
2w
249
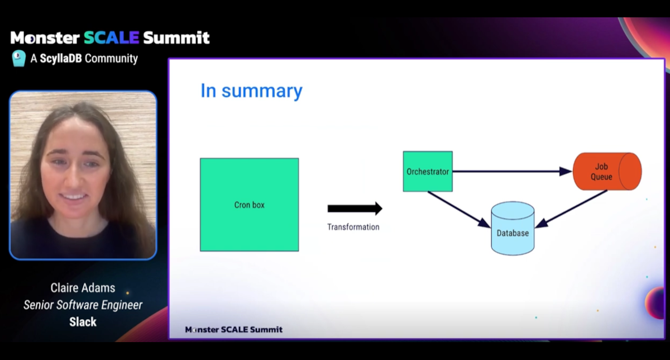
Image Credit: The New Stack
How Slack Transformed Cron into a Distributed Job Scheduler
- Slack transformed its cron jobs into a distributed system due to issues with a single server and increased maintenance time.
- Initially, Slack used a single server to handle cron jobs but faced limitations and downtimes due to out-of-memory errors.
- Moving to a distributed system enabled Slack to increase reliability, reduce maintenance, and gain more job insight.
- Instead of opting for Kubernetes's own cronjob, Slack leveraged its existing asynchronous computing platform and integrated a job execution engine with cron.
- Cron scripts were executed through a dedicated queue wrapped as jobs using Kafka and an AWS EC2 instance.
- Leader election with locking was implemented to ensure a primary server executed all scripts, with backup servers ready to take over swiftly.
- A database was introduced to track script execution statuses, providing centralized information on job runs.
- By leveraging existing systems like Golang and Kubernetes, Slack successfully transitioned to the distributed cron system, reducing on-call burdens.
- The new system has executed over six million scripts with reduced maintenance complexities, highlighting the benefits of utilizing current resources.
- Adams emphasized the importance of simplicity and utilizing available tools to streamline operations and scale efficiently.
Read Full Article
14 Likes
For uninterrupted reading, download the app