A naukri.com initiative
Medium
1M
328
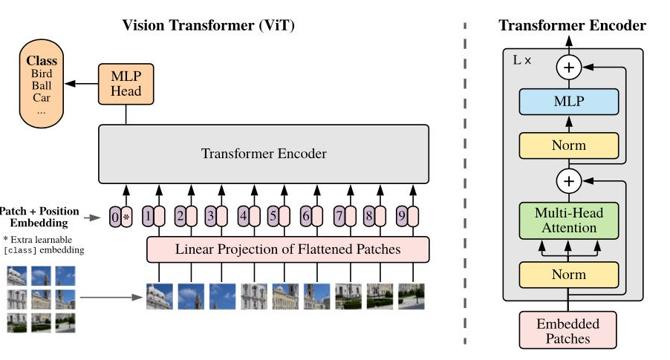
Image Credit: Medium
How to Effectively Train a Vision Transformer for Video-Based Person Re-Identification
- Video-based Person ReID task involves grouping images into tracklets, allowing the model to take advantage of motion patterns and contextual information across frames.
- The two most commonly used metrics in person ReID are Cumulative Matching Characteristics (CMC) curve and mean Average Precision (mAP).
- Pre-training ImageNet-21k is generally the best choice for ViT models.
- Overlapping patch embedding method captures fine-grained details and spatial continuity, thus it enhances feature representation.
- Two effective loss functions in ReID tasks are Cross-Entropy Loss and Triplet Loss, and their combination improves model performance.
- Training with only the first 10 blocks of the Vision Transformer (ViT) base architecture is often adopted to balance computational efficiency and model performance.
- Dividing video sequences into smaller chunks helps in capturing temporal dynamics while reducing computational complexity.
- Using overlapping patches, combining loss functions, and chunking help in achieving state-of-the-art results in video ReID tasks.
- In the next article, the author will provide a more comprehensive guide on fine-tuning and optimizing these approaches for real-world applications.
Read Full Article
19 Likes
For uninterrupted reading, download the app