A naukri.com initiative
Medium
4d
235
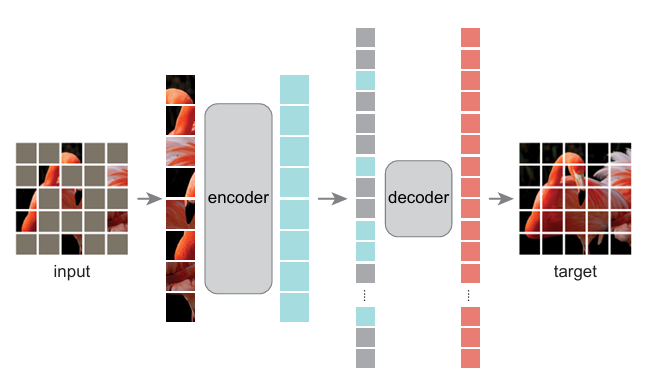
Image Credit: Medium
Masked Autoencoders (MAE): The Art of Seeing More by Masking Most & PyTorch Implementation
- Masked Autoencoders (MAE) scale vision understanding by hiding most of the input image.
- MAE randomly masks 75% of image for model to reconstruct missing pixels efficiently.
- MAE introduces asymmetric setup with strong encoder and small decoder for efficient training.
- MAE's pretraining helps massive models like ViT-H generalize well with ImageNet-1K.
Read Full Article
14 Likes
For uninterrupted reading, download the app