A naukri.com initiative
Pyimagesearch
1M
210
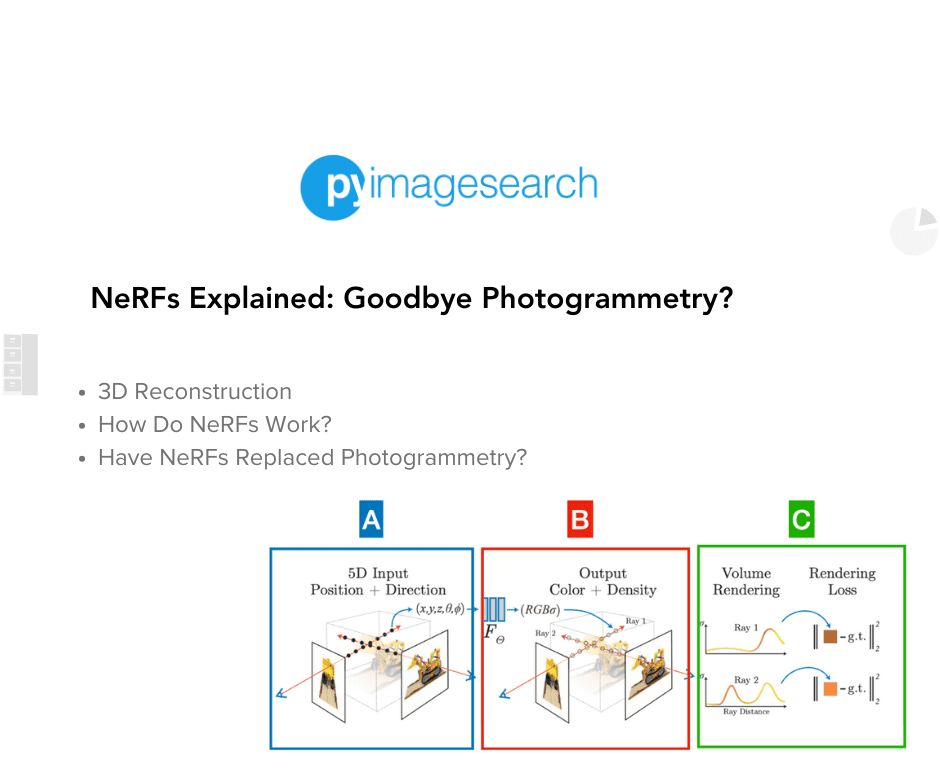
Image Credit: Pyimagesearch
NeRFs Explained: Goodbye Photogrammetry?
- Neural Radiance Fields (NeRFs) removes many of the geometric concepts needed in 3D Reconstruction, particularly in Photogrammetry.
- NeRFs estimate the light, density and color of every point in the air using 3 blocks: input, neural net and rendering.
- Block A: In NeRFs, we capture the scene from multiple viewpoints and generate rays for every pixel of each image.
- Block B: A simple multi-layer perceptron Neural Network in NeRFs regresses the color and density of every point of every ray.
- Block C: To accurately render a 3D scene via volumetric rendering, NeRFs first removes points belonging to the 'air', and then for every point of the ray, learns whether it hits an object, how dense it is, and what’s its color.
- Since its first introduction, there have been multiple versions of NeRFs, from Tiny-NeRFs, to KiloNeRFs and others, making it faster and better resolution.
- Neural Sparse Voxel Fields use voxel-ray rendering instead of regular light ray, making NeRFs 10x faster than before.
- KiloNeRF uses thousands of mini-MLPs, rather than calling one MLP a million times making it 2,500x faster than NeRFs while keeping the same resolution.
- NeRFs have a lot of compute, so it's an offline approach, mainly used for photographing an object and spending around 30+ minutes on its reconstruction.
- NeRFs are pretty effective for generating 3D reconstruction using Deep Learning, but the process can be made faster and easier with newer algorithms such as Gaussian Splatting.
Read Full Article
12 Likes
For uninterrupted reading, download the app