A naukri.com initiative
Medium
6d
128
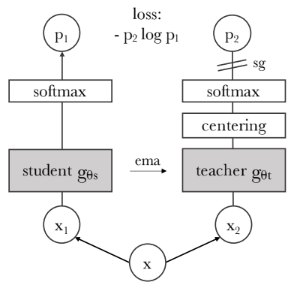
Image Credit: Medium
No Labels, No Problem: How DINO Learns to Understand Images From Scratch
- DINO is a self-supervised learning method that teaches a ViT to understand images without using labels.
- Using a teacher-student approach, DINO trains the student network to mimic the teacher's outputs, enhancing consistency.
- DINO employs multi-crop strategies with global and local views to provide diverse perspectives on images.
- Centering and sharpening techniques prevent model collapse by encouraging diverse feature representation.
- DINO's MLP projection head encourages the model to produce consistent and discriminative features.
- Despite lacking labels, DINO produces representations understanding object structures and spatial layouts.
- In experiments, DINO with ViT architectures outperforms other methods on ImageNet, enabling efficient training.
- DINO-trained features excel in visual tasks like image retrieval, copy detection, and video instance segmentation.
- Ablation study reveals crucial components for DINO's effectiveness, such as momentum encoder and multi-crop training.
- By leveraging ViT architectures, DINO showcases effectiveness in self-supervised learning and downstream task transfer.
Read Full Article
7 Likes
For uninterrupted reading, download the app