A naukri.com initiative
Hackernoon
1w
324
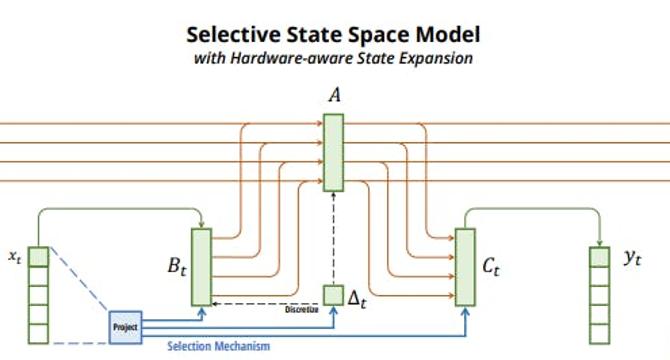
Image Credit: Hackernoon
Princeton and CMU Push AI Boundaries with the Mamba Sequence Model
- Princeton and CMU have developed a new class of selective state space models (SSMs) called Mamba sequence model that operates at subquadratic-time and is more efficient than earlier models for sequence modeling.
- Mamba is a fully recurrent model with properties that make it an appropriate backbone for general foundation models operating on sequences.
- The model is effective in language, audio, and genomics and can scale linearly in sequence length, offering fast training and inference, and allowing for long context.
- Mamba outperforms prior state-of-the-art models such as Transformers on modeling audio waveforms and DNA sequences, both in pretraining quality, and downstream metrics.
- Mamba is the first linear-time sequence model that truly achieves Transformer-quality performance, both in pretraining perplexity, and downstream evaluations.
- Performance improvements have been observed that reach up to 1 million-length sequences.
- The selective SSM's simplicity in filtering out irrelevant information allows the model to remember relevant information indefinitely.
- The hardware-aware algorithm that computes the model recurrently with a scan helps overcome the simple selection mechanism's technical challenge.
- Mamba language model has 5x generation throughput compared to Transformers of similar size and is designed to combine prior SSM architectures with MLP blocks of Transformers into a single homogenous architecture.
- The Mamba-3B model outperforms Transformers of similar size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Read Full Article
19 Likes
For uninterrupted reading, download the app