A naukri.com initiative
Medium
3w
232
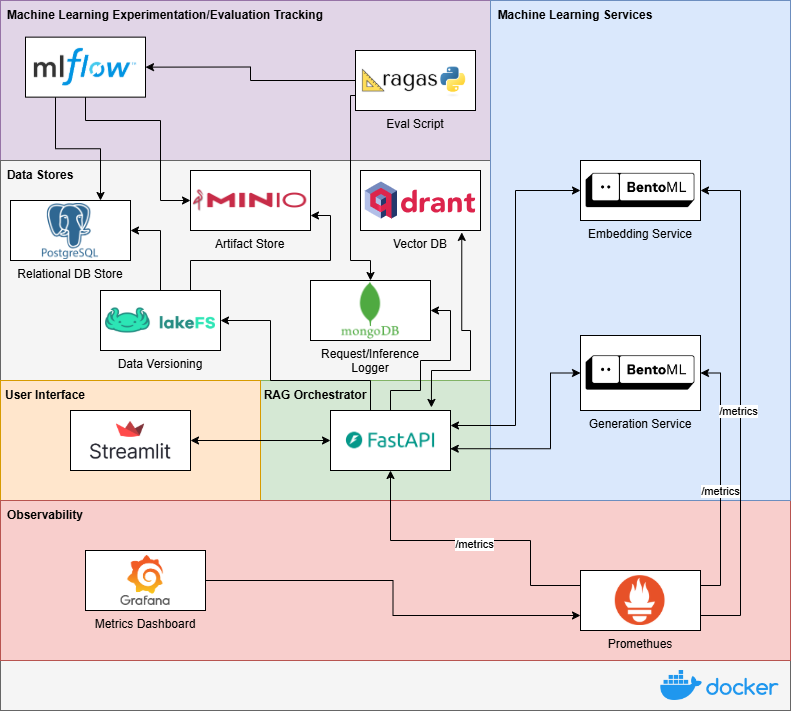
Image Credit: Medium
RAG in Practice: Exploring Versioning, Observability, and Evaluation in Production Systems
- The article discusses the concept of RAG systems and their evolution alongside LLM-powered applications.
- It explores the practical implications of LLMOps, essentially MLOps tailored for large language models, with a focus on RAG systems.
- Key questions addressed include data tracking in RAG systems, evaluation of retrieval quality, and system architecture choices.
- The article highlights the importance of observability, evaluation/testing, reproducibility, modularity, and versioning in RAG systems.
- The author details building a containerized RAG system orchestrated with Docker Compose and utilizing a microservice architecture.
- Challenges in data versioning, traceability, and system evaluation are discussed within the context of RAG systems.
- The exploration includes incorporating monitoring with Prometheus and Grafana, and discussing evaluation methodologies using tools like RAGAS and MLflow.
- The article delves into model deployment considerations, system design choices, and the implications of using hosted LLMs versus self-hosted models.
- Future considerations involve event-driven architectures, enhanced evaluation infrastructure, user feedback mechanisms, and database optimization for RAG systems.
- The author emphasizes the ongoing evolution and learning process in working with RAG systems, seeking feedback and further insights.
- The project serves as a practical exploration of deploying RAG systems, aiming to grasp the nuances of achieving 'production-ready' status in this domain.
Read Full Article
13 Likes
For uninterrupted reading, download the app