A naukri.com initiative
Medium
1M
172
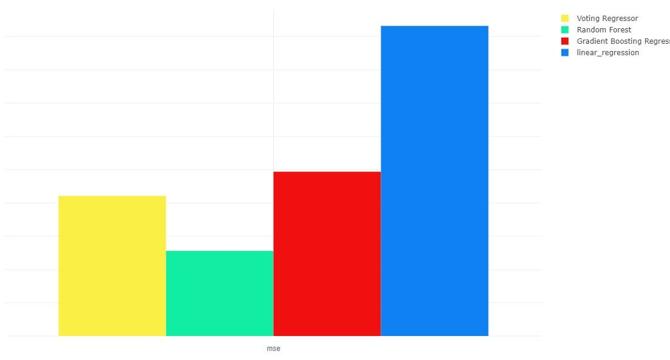
Image Credit: Medium
Revving Up Insights: Predicting Car Prices with Regression Models and Model Interpretability
- The dataset consists of 405,002 rows and 12 columns.
- Data processing techniques were implemented to improve the quality of the dataset.
- A number of features were engineered or simplified to improve the model's interpretability.
- The feature space was reduced using principal component analysis (PCA) and Scikit Learn selection to improve model performance and interpretability.
- Four models were considered: Linear Regression, Random Forest Model, Gradient Boosting Regressor, and Averager/Voting Regressor.
- The performance of each model was compared; the Voting Regressor was found to be the most suitable for this application.
- The SHAP (SHapley Additive exPlanation) algorithm was used to provide global and local explanations of the models.
- The feature importance analysis was executed for each model.
- The model-predicted values were plotted against the actual values for each model.
- The results show that the model is capable of providing accurate car prices within seconds.
Read Full Article
10 Likes
For uninterrupted reading, download the app