A naukri.com initiative
Medium
2d
101
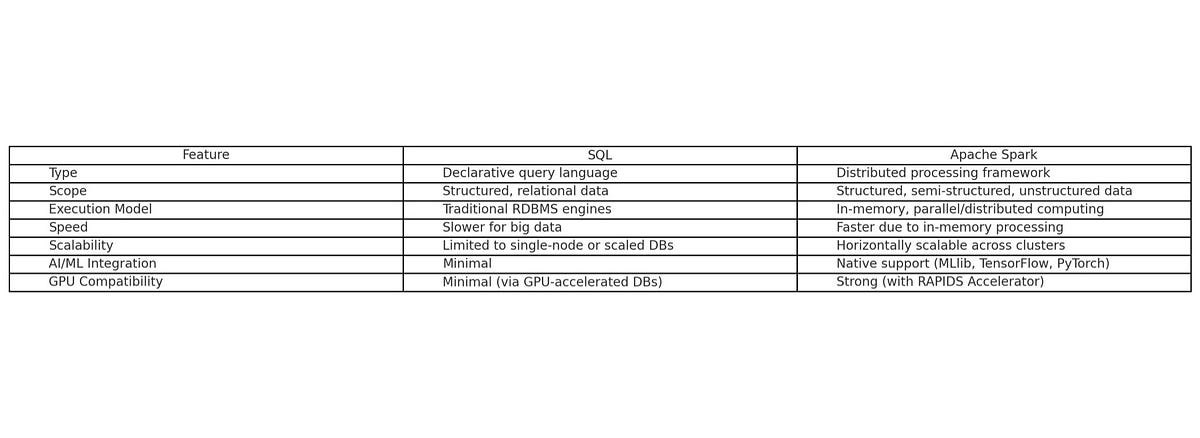
Image Credit: Medium
Spark vs SQL: A Comprehensive Comparison
- Spark SQL and SQL both offer capabilities to query structured data and support ANSI SQL syntax.
- SQL originated in the 1970s and has been fundamental in relational databases and enterprise reporting, while Spark was developed as a faster alternative to Hadoop MapReduce, focusing on in-memory cluster computing.
- SQL is commonly used for OLTP, OLAP, and business intelligence, while Spark is utilized for ETL pipelines, real-time stream processing, machine learning, and more.
- Marketwise, SQL caters to traditional enterprise software and RDBMS, whereas Spark addresses Big Data analytics, AI/ML operations, and real-time data processing.
- The SQL database market is projected to reach over $75 billion by 2028, while the Big Data and Spark-related market is estimated to surpass $130 billion by 2026.
- Spark extensively benefits from NVIDIA GPU compatibility through the RAPIDS Accelerator, providing significant speed enhancements for data processing and ML executions.
- Spark integrates well with various ML frameworks like TensorFlow, XGBoost, and PyTorch, while SQL primarily focuses on basic analytics and lacks strong AI integration.
- In terms of future developments, Apache Spark aims to expand GPU acceleration, enhance Python support, improve Kubernetes integration, and enable AI-native workflows.
- On the other hand, SQL ecosystems are pushing toward cloud-native data warehousing, serverless execution, and increasing AI SQL extensions like Pinecone and Milvus.
- Key players in the SQL ecosystem include Oracle, Microsoft, IBM, Google, Snowflake, and open-source solutions like PostgreSQL and MySQL.
- Within the Spark ecosystem, notable players include Databricks, Cloudera, Amazon EMR, Google Cloud Dataproc, NVIDIA, and Microsoft Azure Synapse Spark.
- Ultimately, while SQL is favored for structured data and enterprise reporting, Apache Spark is recognized for modern data engineering, real-time analytics, and AI workflows, showing strength in GPU-intensive and AI processing tasks.
Read Full Article
6 Likes
For uninterrupted reading, download the app