A naukri.com initiative
Medium
2M
390
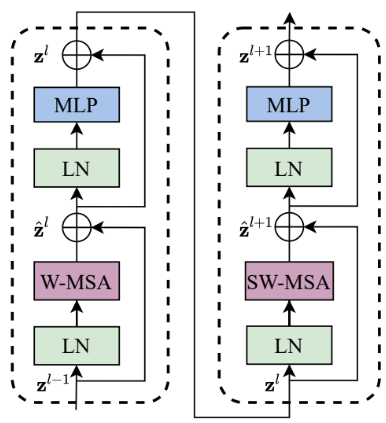
Image Credit: Medium
Swin Transformer in Depth: Architecture and PyTorch Implementation
- The Swin Transformer addresses scale variation and high resolution challenges in visual entities by using a hierarchical feature map and a shifted windowing scheme for self-attention computation.
- Swin Transformer's hierarchical structure enables it to model large and small visual patterns efficiently, with linear computational complexity relative to image size.
- Compared to the Pyramid Vision Transformer (PVT), Swin Transformer excels at both image classification and dense prediction tasks, making it a scalable and efficient option for high-resolution vision applications.
- The Swin Transformer architecture includes stages like Patch Partition, Linear Embedding, Swin Transformer Blocks, and Patch Merging to process high-resolution images and construct a hierarchical feature representation.
- Using a Window-based Multi-Head Self-Attention mechanism and a Shifted Windowing Scheme, the Swin Transformer improves computational efficiency and captures long-range dependencies in visual data.
- In experiments, Swin Transformer showcased superior performance in image classification, object detection, and semantic segmentation tasks when compared to previous state-of-the-art transformer-based models and convolutional neural networks.
- PyTorch Implementation of Swin Transformer involves libraries, Patch Partition, Attention Mask Calculation, Window Based Self-Attention, Patch Merging, and Swin Transformer Blocks among other components.
- Swin-S model outperformed DeiT-S and ResNet-101 in semantic segmentation, and Swin-L model achieved high mIoU on the ADE20K dataset despite having a smaller model size.
- The Swin Transformer's design choices and efficiency make it a robust backbone for various vision applications, showcasing its versatility and effectiveness in handling high-resolution visual tasks.
Read Full Article
23 Likes
For uninterrupted reading, download the app