A naukri.com initiative
Hackernoon
3d
354
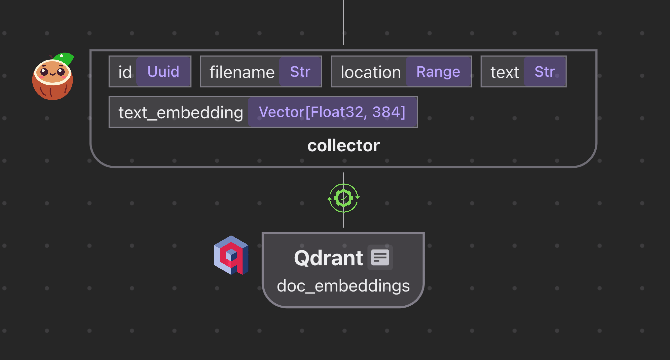
Image Credit: Hackernoon
This Open Source Tool Could Save Your Data Team Hundreds of Hours
- CocoIndex now supports Qdrant natively with high performance Rust stack for incremental processing and data freshness.
- The latest change automates target schema setup with Qdrant from CocoIndex indexing flow, removing the need for manual schema setup.
- Developers no longer have to manually create collections before indexing, as it is now handled automatically.
- The dataflow programming model allows users to define a flow where every step has output data type information.
- Inferred schema setup simplifies operations between indexing and target stores with native integration for Postgres, Neo4j, and Kuzu.
- CocoIndex simplifies setup with commands like cocoindex setup and cocoindex update for running indexing pipelines.
- Automatic target schema inference eliminates the manual effort of setting up and updating target schemas, ensuring data consistency.
- Keeping indexing logic and storage setup in sync can now be streamlined with automatic schema updates in CocoIndex.
- Continuous changes in data systems, like new fields or transformations, emphasize the need for resilient infrastructure.
- CocoIndex aims for declarative, flow-based indexing to enable developers to focus on data and logic rather than infrastructure.
Read Full Article
21 Likes
For uninterrupted reading, download the app