A naukri.com initiative
Medium
1M
388
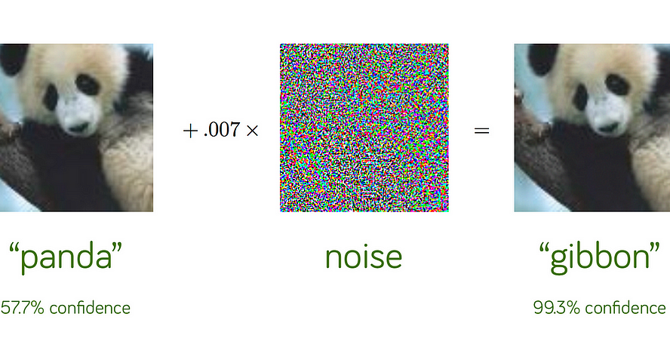
Image Credit: Medium
Understanding Adversarial Attacks in Natural Language Processing
- Adversarial attacks aim to deceive deep learning models by providing misleading or altered input data, exposing weaknesses in AI systems.
- In Natural Language Processing (NLP), adversarial attacks involve making subtle changes to text that confuse AI models while appearing normal to humans.
- These attacks can occur at the character level, word level, or sentence level, and can be combined for higher effectiveness.
- Generating imperceptible adversarial attacks in NLP is challenging due to the noticeable nature of text alterations.
Read Full Article
23 Likes
For uninterrupted reading, download the app