A naukri.com initiative
Towards Data Science
1M
247
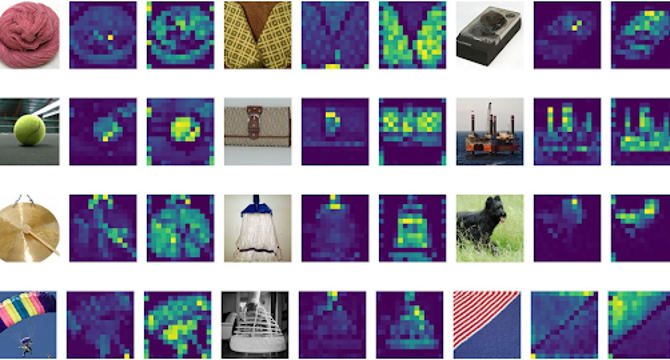
Image Credit: Towards Data Science
Vision Transformers (ViT) Explained: Are They Better Than CNNs?
- Vision Transformers (ViT) aim to implement image classification by applying self-attention globally using the Transformer encoder architecture, outperforming conventional CNNs like ResNet with less computational resources.
- Transformers, initially introduced by Vaswani et al., operate on sequential data like text through self-attention, weighing the importance of each element relative to others, simplifying complex tasks in NLP.
- Self-attention mechanism in transformers captures relationships within a sequence, aiding tasks like translation through contextual understanding of words.
- A transformer transforms input using encoder and decoder blocks with self-attention; the encoder block includes key (K), query (Q), and value (V) sets derived via trainable weight matrices.
- Multi-headed self-attention in transformers enhances performance by allowing different heads to learn distinct relationships, boosting contextual understanding and dealing with variations.
- Vision Transformers process images as sequences of tokens, not pixels, reducing attention map dimension while handling varied image sizes without drastic architectural changes.
- ViT incorporates linear embeddings, positional encodings, and a learnable classifier to preprocess image patches before inputting them into the Transformer encoder for classification.
- ViT models pre-trained on JFT-300M dataset outperform ResNet-based models across datasets, demonstrating superior performance with less pre-training computational resources.
- ViT processing performance excels when pre-trained on extensive datasets but may lack inductive biases present in CNNs on smaller datasets.
- Further advancements in ViT technology could involve scaling for tasks like image detection, segmenting, and developing smaller, more efficient ViT architectures.
Read Full Article
14 Likes
For uninterrupted reading, download the app