A naukri.com initiative
AI News
Medium
54

Image Credit: Medium
When you’re working with large volumes of unstructured text — whether it’s support tickets, survey…
- Custom stop words can be used to remove non-essential keywords for better analysis.
- Traditional topic modeling like LDA may not work well with short or subtle language.
- Transformers like MiniLM-L6-v2 model from sentence-transformers library represent sentences as vectors for better analysis.
- GPT can provide clear, business-readable summaries for better interpretation of topics identified.
Read Full Article
3 Likes
TechCrunch
70

Image Credit: TechCrunch
Research leaders urge tech industry to monitor AI’s ‘thoughts’
- AI researchers urge deeper investigation into monitoring AI's reasoning models' thoughts.
- Position paper by leaders from OpenAI, Google DeepMind, and more advocates for CoT monitoring.
- CoTs offer insight into AI decision-making, crucial as AI agents advance.
- Authors stress the importance of preserving and understanding CoT monitorability for AI safety.
Read Full Article
3 Likes
Medium
222
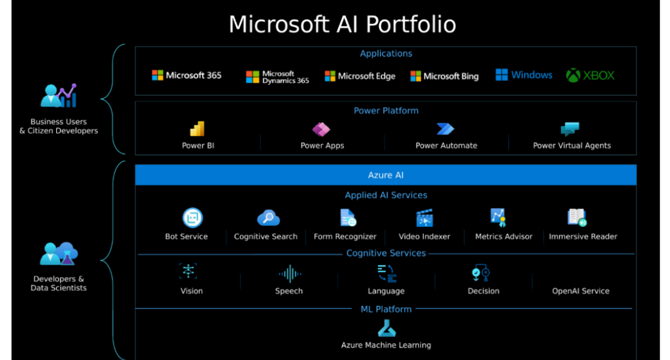
Image Credit: Medium
Top 5 Courses to Learn Azure AI Studio in 2025
- Microsoft’s Azure AI Studio is a powerful platform for building, evaluating, and deploying intelligent applications, making it a valuable skill for career growth in 2025.
- Top Udemy courses for learning Azure AI Studio in 2025 are focused on practical, hands-on experience with features like Prompt Flow, RAG, LLMOps, and more.
- Courses cover topics such as building AI-powered copilots, preparing for Azure certifications, bridging machine learning and generative AI, and deploying conversational copilots using Microsoft technologies.
- Enrolling in these courses can help individuals upskill for work, enhance their AI knowledge, and set a foundation for practical applications in Azure AI Studio and Microsoft Copilot Studio.
Read Full Article
13 Likes
Siliconangle
254

Image Credit: Siliconangle
Qdrant launches Cloud Inference for multimodal vector search with higher speed and lower cost
- Qdrant has launched Qdrant Cloud Inference, a managed service enabling developers to search text and image vectors simultaneously.
- This new service by Qdrant aims to simplify workflows by combining text and image embedding and vector search processes into one tool.
- Qdrant's Cloud Inference reduces latency, cuts network costs, and simplifies search for developers working on AI-driven applications.
- The service supports multimodal search capabilities using various models and algorithms, including TM25 and CLIP for text and image.
Read Full Article
15 Likes
Medium
180

Image Credit: Medium
AI Gave Me Code That Looked Right — Then It Took Down Production
- The writer experienced a production server outage with an HTTP 500 error.
- The issue was caused by AI-generated code that appeared correct but brought down the system.
- The incident highlighted the potential risks of relying solely on AI code-generation tools for production systems.
- The writer learned from the experience and now approaches code written by AI tools with more caution to prevent future failures.
Read Full Article
10 Likes
TechCrunch
214

Image Credit: TechCrunch
Mistral releases Voxtral, its first open source AI audio model
- French AI startup Mistral has released Voxtral, its first open model aimed at challenging closed corporate systems in the AI audio space.
- Voxtral offers affordable and usable speech intelligence for businesses, claiming to be less than half the price of comparable solutions.
- Mistral's Voxtral can transcribe up to 30 minutes of audio and is multilingual, capable of transcribing and understanding various languages.
- Mistral offers two variants of its speech understanding models, Voxtral Small for larger deployments and Voxtral Mini for local and edge deployments, at competitive prices.
Read Full Article
12 Likes
Knowridge
39
Image Credit: Knowridge
How ChatGPT is giving stroke survivors a new way to communicate
- Researchers at the University of Technology Sydney are using ChatGPT and AI to support stroke survivors with aphasia, a language disorder affecting communication.
- Nathan Johnston, a stroke survivor, has improved his communication using ChatGPT, moving from single-word messages to composing texts and emails.
- Students at UTS assist Johnston in using ChatGPT during therapy sessions to create more complex and meaningful messages, marking significant progress for aphasia patients.
- While AI tools like ChatGPT offer great potential in improving communication for individuals with aphasia, challenges exist, such as adapting to polished tones and ensuring accessibility for all users.
Read Full Article
2 Likes
Pcgamer
93

Image Credit: Pcgamer
Meta is expanding its AI capabilities so quickly it's housing data centers in tents, which would make them data tenters, no?
- Meta is rapidly expanding its AI hardware capabilities and has resorted to housing some of its AI data center hardware in tents to keep up with the pace of AI development.
- A SemiAnalysis report revealed that Meta's tent-based infrastructure is set up due to the slow process of constructing traditional buildings to accommodate AI hardware, which cannot keep up with the speed of AI progress.
- While a Meta spokesperson confirmed the use of tent-based infrastructure, it is likely that these tents house ancillary racks connected to a main cluster nearby, as cooling remains a significant challenge for such setups.
- Meta's CEO Mark Zuckerberg announced plans to build massive multi-gigawatt superclusters like Prometheus and Hyperion, aiming for operational efficiency and large-scale data processing capabilities, although the ecological impact of such rapid expansion remains a topic of concern.
Read Full Article
5 Likes
Global Fintech Series
143

Image Credit: Global Fintech Series
Billtrust Unveils Major Collections Software Innovations, Ushering in a New Era of AI-Powered, Intelligent Accounts Receivable
- Billtrust announced major innovations in its Collections solution, incorporating advanced automation, AI-driven insights, and agentic AI workflows to enhance accounts receivable operations.
- New features include Agentic Email, Cases for dispute management, Credit Review for ongoing credit risk assessment, and Collections Analytics for real-time performance optimization.
- These innovations aim to streamline collections, resolve disputes faster, make smarter credit decisions, and deliver a better customer experience from a single platform.
- The CEO emphasized that Billtrust is delivering the future of collections with intelligent, automated, and customer-centric solutions, helping organizations modernize their operations and enhance performance.
Read Full Article
8 Likes
Global Fintech Series
384

Image Credit: Global Fintech Series
Wiv.ai Launches Game-Changer: The First FinOps Agent That Actually Takes Action
- Wiv.ai has launched Wivy, the First FinOps Agent that can take action, revolutionizing FinOps by enabling automated execution of operations powered by artificial intelligence.
- Wivy allows teams to perform tasks like identifying unattached EBS volumes, handling top tasks for the day, finding resources without proper tags, and recommending cost-saving rightsizing for instances.
- The agent integrates with major cloud platforms, communication tools, and management systems, adapting to organizations' specific workflows and processes.
- Wivy ensures privacy by not learning on customer data and allowing customers to use their own AI models, leading to improved response time, cost savings, task accuracy, and continuous operation for organizations.
Read Full Article
23 Likes
Global Fintech Series
816

Image Credit: Global Fintech Series
Diversify Partners with Jump to Boost Advisor Productivity with AI-Powered Productivity Tools
- Diversify partners with Jump to provide advisors with AI-powered productivity tools to enhance client meetings, documentation, and follow-ups.
- The collaboration enables Diversify advisors to access Jump's suite of intelligent tools, streamlining workflows and reducing administrative burdens.
- Advisors have reported increased productivity with Jump, allowing them to focus on building trust with clients and meeting their needs effectively.
- Diversify aims to empower advisors by removing barriers and offering world-class support, reinforcing its commitment to assisting advisors in serving clients efficiently.
Read Full Article
21 Likes
Dev
229

Image Credit: Dev
A Summer of Security: How Google’s AI-Led Cybersecurity Push Is Changing the Game
- Google launched a series of cybersecurity advances under 'A Summer of Security,' introducing groundbreaking shifts for cybersecurity worldwide.
- The key takeaways include Big Sleep AI for vulnerability finding, Secure AI Framework for secure AI design, FACADE & Timesketch for analyst support, and CoSAI for collective intelligence.
- These advancements aim to enhance threat detection, integrate security by default in AI, empower analysts with AI tools, and promote shared intelligence to combat emerging threats.
- Google is deploying region-specific security measures in India to help prevent cybercrime, emphasizing real-time fraud warnings and AI-driven filters to protect users.
Read Full Article
4 Likes
Insider
40

Image Credit: Insider
Nvidia stock jumps after the AI titan says it can sell some of its top chips to China again
- Nvidia stock surged 5% after the announcement of resuming sales of H20 chips to China.
- CEO Jensen Huang met with President Trump to discuss US AI dominance goals.
- Morgan Stanley CIO sees this as a positive sign for the AI sector.
- The US government will allow Nvidia to ship H20 chips to China again, potentially boosting margins.
Read Full Article
2 Likes
Pymnts
155

Image Credit: Pymnts
Google AI Chatbot Target of Potential Phishing Attacks
- A security threat in Google's AI chatbot was discovered by researchers.
- The issue involves a prompt-injection flaw that allows cybercriminals to create phishing or vishing campaigns by embedding malicious prompts in emails.
- Google is implementing updated defenses to combat prompt injection-style attacks after discussions in a company blog post.
- The breach of McDonald's AI hiring chatbot also highlights the importance of cybersecurity strategies in the face of evolving cyber threats.
Read Full Article
9 Likes
Medium
23

The Art of the Algorithm: How AI is Revolutionizing Visual Storytelling
- AI is evolving in visual storytelling from simple image generation to becoming a partner in ideation and creation, speeding up processes significantly.
- AI tailors content to individual viewers, leading to hyper-personalized experiences and strong engagement.
- AI streamlines visual production processes, reducing time and costs, democratizing high-quality content creation.
- AI provides analytical capabilities for creators to optimize visual content performance and refine narratives for better resonance.
Read Full Article
1 Like
For uninterrupted reading, download the app