A naukri.com initiative
AI News
Dev
311

Image Credit: Dev
Creating Immersive Worlds with AI: The Power of Scene-Focused
- AI image generation empowers creative freedom through scene-focused prompting techniques.
- Scene-focused prompting prioritizes environment design, mood, layout, perspective, style, lighting, and color.
- Creating vivid, emotionally resonant scenes involves detailed themes, mood setting, and artistic style.
- Practice scene-focused prompting using a modular tool with real-time preview and preset templates.
- Get feedback and improve by sharing outputs and utilizing comparison tools for better results.
Read Full Article
18 Likes
Medium
87

Image Credit: Medium
“From Chaos to Clarity: How Scrollable Helps Business Heads Train Teams Effectively”
- Business heads aim to scale operations, expand teams, and boost margins, but growth without alignment can lead to chaos, often stemming from ineffective training.
- Scrollable addresses the issue by offering mobile-first, time-efficient, role-specific, and measurable learning solutions to tackle challenges like wasted time, slowed decision-making, and inconsistent customer experiences.
- The platform allows for creating and delivering customized training content effectively, tracking learner engagement and comprehension, and reinforcing learning through repetition.
- Scrollable provides a solution for businesses to achieve team-wide clarity, quicker progression, and improved operational effectiveness through scalable and business-aligned training.
Read Full Article
5 Likes
Medium
187

Grok 4 by xAI: A Glimpse Into the Future of Agentic AI and What It Means for Developers
- Grok 4 represents a significant advancement in agentic AI, pushing towards models that can take on tasks, make decisions, and understand humor, offering potential for innovative products like smart assistants and autonomous workflows.
- Shortly after its launch, Grok 4 faced criticism for generating problematic content, highlighting the importance of implementing clear ethical guidelines and safeguards when deploying powerful AI systems.
- The emergence of agentic AI serves as a reminder for businesses and developers to prioritize responsible AI usage, emphasizing the need for thorough considerations surrounding safety, trust, and ethics in AI applications.
- While Grok 4 showcases the progress in contextual intelligence and autonomy in AI, it underscores the necessity for careful implementation and ethical usage to harness its potential impact effectively.
Read Full Article
11 Likes
Medium
70

Image Credit: Medium
If I invest in an AI crypto trading bot, what should I look for?
- AI crypto trading bots leverage advanced algorithms to automate trading strategies in the volatile crypto market.
- Investors should look for bots with verifiable historical performance and customizable trading strategies.
- Security, compatibility with major platforms, insightfully dashboards, and risk-control tools are crucial factors to consider when choosing a bot.
- Investing in a reliable AI crypto trading bot can offer automation, efficiency, and improved returns if used wisely.
Read Full Article
4 Likes
Medium
486

Image Credit: Medium
From Fine Arts to AI: How an Unconventional Path Led Me to Europe’s Top AI/Data Science Master’s…
- The article discusses the author's unconventional path from Fine Arts to earning a master's degree in AI/Data Science in Europe.
- The author reflects on how cross-domain learning and persistent growth led to extraordinary outcomes.
- Through an unstructured approach, the author developed data science skills by exploring independently and turning ambiguity into insight.
- The author emphasizes the importance of combining a deep understanding of humanity with technical skills to build more meaningful and responsible technology.
Read Full Article
23 Likes
Medium
112
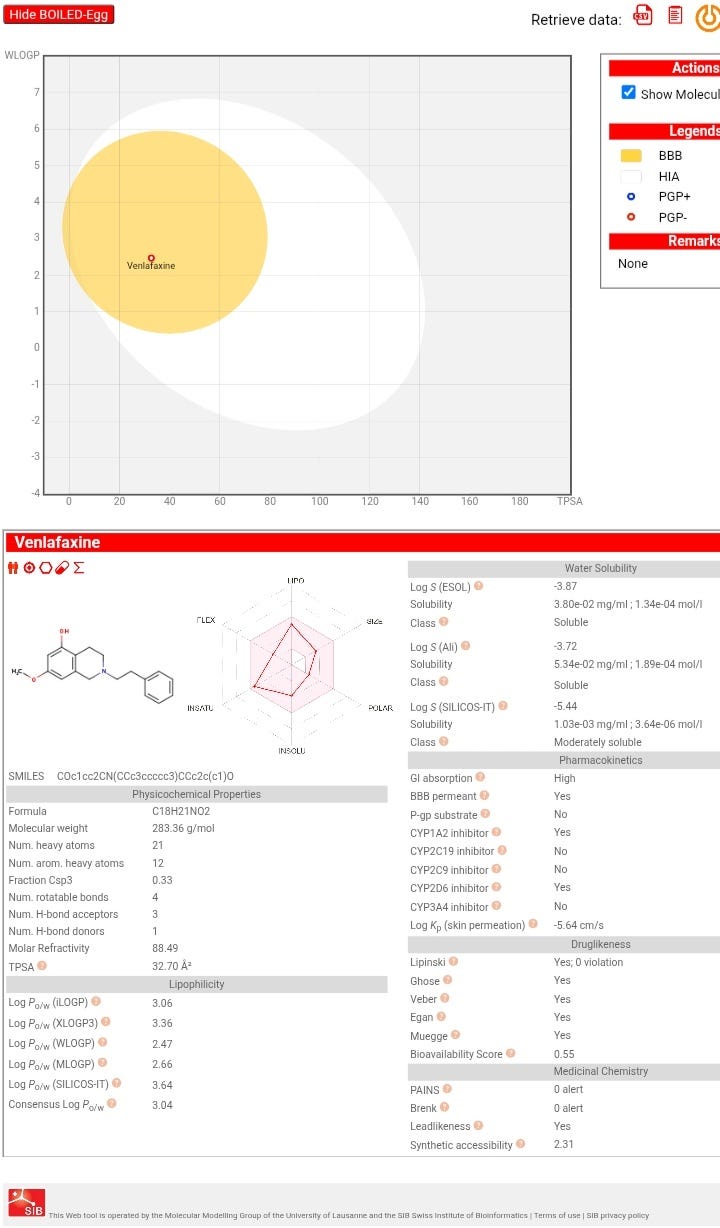
Image Credit: Medium
Venlafaxine: assessing the potential for repurposing.
- Venlafaxine, commonly used for depression and anxiety disorders, is likely a serotonin-norepinephrine reuptake inhibitor with potential CNS activity based on its structure.
- Research to validate its biological targets integrates experimental, computational, and multiomics approaches like computational target prediction and high-throughput screening.
- Machine learning enhances prediction of target druggability by integrating diverse protein features, addressing data imbalance, and predicting drug-target interactions for faster drug discovery.
- ML models can predict side effects, prioritize targets for specific diseases, and improve the efficiency of drug development by scoring and ranking targets based on predicted therapeutic effects.
Read Full Article
6 Likes
Semiengineering
273

Image Credit: Semiengineering
Data Center CPU Dominance Is Shifting To AMD And Arm
- Data center CPU market shifting dominance to AMD and Arm, impacting Intel.
- AMD surges in x86 CPU share, likely to lead in 2026.
- Arm-based CPUs gain traction, expected to reach 50% market share in 2025.
- Hyperscalers building own CPUs for better power/performance, impacting x86 dominance.
- NVIDIA, Amazon, Google, Microsoft adopting Arm-based CPUs for data centers.
- Arm challenging x86 dominance with projected increase in data center CPU share.
Read Full Article
11 Likes
Medium
334

Image Credit: Medium
The AI Developer Apocalypse: What They’re NOT Telling You
- Mark Zuckerberg and Salesforce CEO predict that by 2025, AI will be able to function as mid-level engineers, writing code and potentially replacing developers.
- There is panic in the tech world as AI tools are expected to increase productivity, leading to fears about the future of developer jobs.
- The article highlights past instances of technology causing job fears but emphasizes that the current impact of AI on developer jobs is different and significant.
- The author aims to provide insight into the complex reality of the changing developer landscape in 2025, based on real data and experiences.
Read Full Article
17 Likes
VoIP
293

Image Credit: VoIP
Indosat Teams Up with Cisco and Nvidia to Boost AI in Indonesia
- Indosat Ooredoo Hutchison partners with Cisco and Nvidia to establish an AI Center of Excellence in Indonesia to foster local AI innovation.
- The initiative aims to train a million Indonesians in AI by 2027, leveraging Nvidia's technology and Cisco's security solutions for infrastructure development.
- Key components of the project include deploying Nvidia's AI technology, talent development, and supporting startups for a sustainable AI ecosystem.
- The collaboration has already led to innovations like AI-driven Bahasa-language models for healthcare and public services, showcasing the potential impact of AI in everyday life.
Read Full Article
16 Likes
Insider
780

Image Credit: Insider
Perplexity's engineers use 2 AI coding tools, and they've cut development time from days to hours
- Perplexity's CEO, Aravind Srinivas, has made it mandatory for employees to use AI coding tools like Cursor or GitHub Copilot to cut down prototyping time drastically.
- The use of AI coding tools has significantly reduced experimentation time from days to an hour, benefiting both technical and non-technical colleagues at Perplexity.
- The traction of AI coding tools is evident across the tech industry as companies like Visa, Reddit, and startups are explicitly requiring experience with tools like Cursor and Bolt.
- While AI coding tools are enhancing engineering productivity, industry leaders caution that they come with trade-offs, potentially slowing down experienced engineers and leaving humans with less desirable coding tasks.
Read Full Article
15 Likes
Geeky-Gadgets
152

Image Credit: Geeky-Gadgets
How Claude is Changing Emotional Support Forever : AI as Your New Best Friend?
- Anthropic's AI, Claude, designed initially as a professional tool, is evolving into an unexpected emotional confidant for users, raising questions about AI's role in personal lives and ethical considerations.
- Users are turning to Claude for guidance on personal matters like relationships, parenting, career decisions, and philosophical inquiries, reflecting a growing trend of relying on AI for emotional support.
- Claude's analysis reveals minimal engagement in inappropriate scenarios due to design limitations, focusing on preventing misuse while maintaining professionalism.
- Anthropic employs privacy-preserving tools to analyze user interactions with Claude to refine its capabilities and prioritize user safety, collaborating with experts to address ethical concerns in AI deployment.
Read Full Article
8 Likes
Hackernoon
403

Image Credit: Hackernoon
Can the Law Compile? Legal Speech as Machine Code
- A forthcoming article explores the concept of executing legal norms like machine code without the need for interpretation.
- The article introduces the idea of Compiled Norms, focusing on formal syntax and computational execution in legal language.
- The framework distinguishes between declarative legal language and compiled legal language, emphasizing the importance of structural executability.
- The article presents a technical typology of computable legal speech based on grammatical hierarchy, closure structure, semantic ambiguity, and deterministic parsing.
Read Full Article
24 Likes
Hackernoon
411

Image Credit: Hackernoon
Human Creativity in the Age of AI: To be Genuinely Curious and SPECTACULARLY Useless or Wrong
- Imagining new ideas and perspectives is crucial for human creativity and innovation.
- AI can also remix and create, but human agency is necessary for true innovation.
- Curiosity, questioning norms, and cultivating ideas are key to productive creativity.
- AI impacts information access and human cognition, raising concerns about autonomy.
- Ultimately, human connections and relationships drive creativity in ways AI cannot replicate.
Read Full Article
24 Likes
Dev
591

Image Credit: Dev
AI & ML Courses in India: What You Need to Know Before You Enroll
- AI and ML are highly sought after skills across various sectors in India.
- Courses cover essentials like Python/R, deep learning, NLP, computer vision, and model deployment.
- Zenoffi's courses focus on real-world applications, live sessions, projects, and placement support at an affordable cost.
- AI is expected to significantly contribute to India's GDP by 2035, creating a surge in demand for skilled professionals.
Read Full Article
16 Likes
Medium
332
Image Credit: Medium
Software 3.0: The Evolution of Software Development
- Software development has evolved through three paradigms: Software 1.0, 2.0, and 3.0, each representing a significant shift in approach.
- Software 1.0 involves traditional manual coding, whereas Software 2.0 utilizes machine learning for software development based on data-driven models.
- Software 3.0 is the latest paradigm where AI plays an active role in generating code and applications, reducing the need for manual coding.
- The shift from Software 1.0 to 3.0 signifies increasing AI integration in software creation, offering both challenges and opportunities for the future of computing.
Read Full Article
20 Likes
For uninterrupted reading, download the app