A naukri.com initiative
ML News
Amazon
40
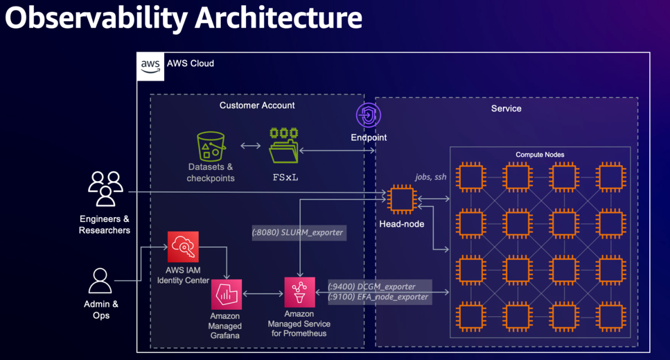
Image Credit: Amazon
Accelerating Articul8’s domain-specific model development with Amazon SageMaker HyperPod
- Articul8 is accelerating their training and deployment of domain-specific models using Amazon SageMaker HyperPod, achieving over 95% cluster utilization and a 35% improvement in productivity.
- SageMaker HyperPod provides fault-tolerant compute clusters, efficient cluster utilization through observability, and seamless model experimentation using Slurm and Amazon EKS.
- Articul8 develops domain-specific models for industry sectors like supply chain, energy, and semiconductors, achieving significant accuracy and performance gains over general-purpose models.
- The A8-SupplyChain model achieves 92% accuracy and threefold performance gains over general-purpose models.
- SageMaker HyperPod enabled Articul8 to rapidly iterate on DSM training, optimize model training performance, and reduce AI deployment time and total cost of ownership.
- The platform offers efficient cluster management, automated failure recovery, and observability through Amazon CloudWatch and Grafana.
- Articul8's setup with SageMaker HyperPod and Managed Grafana empowered rapid experimentation, leading to superior real-world performance for domain-specific models.
- The cluster setup includes head and compute nodes, shared volumes, local storage, Slurm scheduler, and accounting for job runtime information.
- Articul8 confirmed the performance of A100 and achieved near linear scaling with distributed training, reducing training time significantly.
- Through SageMaker HyperPod, Articul8's DSMs demonstrated superior performance, accelerated AI deployment time, and lowered total cost of ownership.
Read Full Article
2 Likes
Amazon
22

Image Credit: Amazon
How VideoAmp uses Amazon Bedrock to power their media analytics interface
- VideoAmp collaborated with AWS to develop a prototype of the VideoAmp Natural Language (NL) Analytics Chatbot using Amazon Bedrock for media analytics data analysis.
- The AI solution included a natural language to SQL pipeline and an automated testing tool for analytics queries.
- VideoAmp, a tech-first measurement company, uses AI to enhance measurement and optimization capabilities for TV, streaming, and digital media.
- Their AI journey focuses on providing accurate audience insights, improving measurement, and optimizing ad campaigns in real-time.
- VideoAmp is set to launch an AI analytics interface powered by generative AI to offer accessible insights through natural language queries.
- The solution aimed to convert natural language questions to SQL, execute queries on performance metrics data, and provide natural language summaries.
- Challenges included adapting large language models (LLMs) and developing an automated evaluation pipeline for accurate results.
- Amazon Bedrock, with Anthropic’s Claude 3 LLMs, was used for the AI assistant, providing models for SQL generation and data summarization.
- The solution connected to a data warehouse and supported various database connections, enhancing analytics capabilities.
- The evaluation framework ensured high accuracy, low latency, and cost-effectiveness for user queries, meeting VideoAmp's expectations.
Read Full Article
1 Like
Medium
85

Avalanches of Meaning: Applying the Brain's Power Law Geometry to AI Language Models
- The article explores the merging of neuroscience principles with Large Language Models (LLMs) in the context of meaning generation.
- Neuroscience reveals brain activity follows a 'power law' and operates in high-dimensional geometries, similar to LLM capabilities.
- The brain's power-law dynamics allow for stability and flexibility, enabling meaningful cognition through neural avalanches.
- The Semantic Collapse Function scores the significance of ideas based on coherence, relevance, and novelty, altering standard LLM outputs.
- LLMs typically prioritize statistical likelihood over semantic significance, prompting the proposal to shift to prioritizing meaning.
- The Semantic Avalanche Model alters LLM behavior to prioritize profound, meaningful structures over common outputs, simulating human insight.
- This model introduces the concept of Semantic Mass and a selection process emphasizing semantic coherence and rarity in outputs.
- The proposed architecture mirrors human brain insight processes, aiming to create AI systems that simulate cognitive avalanches of meaning.
- The unified equation of the Semantic Avalanche Model guides AI in selecting outputs based on brain-like principles of coherence and power-law distribution.
- The article concludes by suggesting that combining neuroscience, semantic resonance mathematics, and structured LLM architectures can lead to the creation of systems that generate highly meaningful symbolic collapses.
- Eligible for Web Story: True
Read Full Article
5 Likes
Medium
22

Image Credit: Medium
Who’s Responsible When AI Fails?
- When AI fails, the issue of responsibility arises, as AI systems can make mistakes despite their perceived accuracy.
- AI is created by people but behaves differently as it learns from itself, making decisions that may not be fully understood by its creators.
- The use of AI in real-life scenarios, such as aiding judges in predicting repeat crimes, has led to instances of bias and errors.
- AI, while often perceived as neutral, actually learns from the data it is fed, which can contain biases and prejudices.
- Concerns about responsibility in AI are growing, particularly when AI systems make incorrect recommendations or decisions with significant consequences.
- Calls for greater transparency in AI development and a shift towards a culture of accountability and ethical considerations are becoming more prominent.
- AI can have positive impacts but also poses risks, highlighting the importance of addressing accountability in the development and deployment of AI technologies.
- There is a need to consider the implications of AI failures and ensure that mechanisms are in place to assign responsibility when things go wrong.
- Building a culture where moral considerations and responsibility are prioritized can help mitigate the potential negative impacts of AI failures.
- Ultimately, understanding who holds responsibility for AI failures is crucial for ensuring the ethical and accountable use of AI technologies.
Read Full Article
1 Like
Medium
100

Image Credit: Medium
Salaries in the Tech Industry — What Influences Your Income?
- Tech jobs are highly sought after, and factors influencing developer salaries were analyzed using the Stack Overflow Survey 2024 data.
- The survey encompassed insights into programming languages, working conditions, and salaries of over 50,000 developers worldwide.
- Salaries in the tech industry vary widely, ranging from six-figure incomes to lower salaries.
- Factors like professional experience, education level, and location significantly impact salary levels.
- A Random Forest model was built to predict salaries based on different variables.
- Location emerged as the most crucial factor influencing salaries, with over 51% influence.
- Professional experience followed, accounting for about 20% of salary influence.
- The type of developer role, programming languages mastery, and company size also play a significant role in determining salaries.
- Education was found to have a lesser impact on salaries compared to practical skills and experience.
- Remote work and age were identified as factors with lesser influence on salary levels.
- Moving to a country with higher salary levels may be more financially rewarding than focusing solely on educational qualifications or specific programming languages.
- These insights can aid both new and experienced developers in career planning and setting realistic salary expectations.
- For detailed technical information on the analysis, the complete code and methodology are available on the author's GitHub repository.
Read Full Article
6 Likes
Medium
160

Image Credit: Medium
Why AI Needs an “Oral Defense” — A New Approach to Model Validation
- AI systems are advancing rapidly with capabilities like acing medical boards and drafting legal contracts.
- There is a concern about how to validate if these AI systems truly understand the tasks they perform.
- The author, a physician and immunologist, questions the readiness of AI systems for practical use.
- There is a need to move beyond static benchmarks to assess AI models.
- The author proposes bringing the oral defense paradigm from academia to the validation of AI models.
- Questions about AI models' comprehension and understanding need to be addressed.
- The limitations of current evaluation methods need to be acknowledged and tackled.
- It's suggested that engaging with complex questions now is better than facing failures later.
- The hope is that this approach will lead to new discussions and collaborations in the field of AI validation.
Read Full Article
9 Likes
Global Fintech Series
1.4k

Image Credit: Global Fintech Series
Automating AML Investigations with AI and Machine Learning
- Financial crime, including money laundering and fraud, is evolving rapidly with increasing complexity and sophistication.
- Current AML methods relying on manual processes struggle to keep up, resulting in high false positives and missed threats.
- AI and ML redefine AML investigations, enabling real-time anomaly detection, automated risk assessment, and proactive fraud prevention.
- The article explores how AI and ML are transforming AML investigations by automating processes and reducing false positives.
- Financial institutions face challenges in detecting financial crime due to the complexities of modern criminal activities and evolving regulatory landscape.
- Cryptocurrencies, DeFi, and cyber threats add layers of complexity, making it harder for institutions to monitor illicit activities.
- Financial fraud driven by cybercrime, synthetic identities, and ransomware poses significant challenges for traditional AML systems.
- Regulators are increasing scrutiny and penalties for non-compliance, emphasizing the need for more adaptive AML solutions.
- AI and ML help overcome AML compliance challenges by providing intelligent pattern detection, reducing false positives, and enhancing customer risk profiling.
- The integration of AI in AML processes enhances efficiency, reduces false positives, enables real-time anomaly detection, and offers a scalable approach to financial crime detection.
Read Full Article
10 Likes
Medium
297

Image Credit: Medium
How to Generate Synthetic Time-Series Data on Databricks
- Leveraging time-series datasets involves challenges like variability, representativity, and granularity for time-dependent variables, hindering AI model development.
- Synthetic data helps overcome these challenges by providing diverse, privacy-compliant datasets for accurate time-series analysis on the Databricks platform.
- Generating synthetic time-series data is crucial for capturing observed patterns and complexities in datasets like Walmart store sales data from Kaggle.
- Tools like TimeGAN and DoppelGANger offer solutions but can be hard to tune; YData Fabric simplifies time-series synthetic data generation in Databricks.
- Using ydata-sdk in Databricks enables data profiling, synthetic data exploration, and efficient training of generative models for time-series data.
- Configuring and training the synthetic data generator with YData Fabric involves optimizing model selection and parameters based on metadata search.
- Understanding dataset aspects like entities and time-series behaviors is crucial for generating multiple synthetic samples with fidelity.
- Combining original and synthetic data sets allows for applications like building forecasting models for weekly sales in retail scenarios.
- The integration of ydata-sdk with Databricks streamlines data quality and privacy compliance, enabling synthetic time-series data generation for advanced predictive models.
- This integration enhances data robustness, reduces overfitting, and simplifies workflow for data access and preparation in large-scale scenarios.
Read Full Article
17 Likes
Arxiv
243
Image Credit: Arxiv
Llama-Affinity: A Predictive Antibody Antigen Binding Model Integrating Antibody Sequences with Llama3 Backbone Architecture
- Antibody-facilitated immune responses are crucial for defense against pathogens and viruses.
- Bioengineering advancements have accelerated therapeutic antibody development.
- AI and machine learning have revolutionized affinity prediction for antibodies.
- A new model, LlamaAffinity, integrates antibody sequences with Llama 3 backbone architecture.
- The model outperforms existing methods like AntiFormer and AntiBERTa in affinity prediction.
- LlamaAffinity achieved high accuracy, F1-score, precision, recall, and AUC-ROC values.
- It demonstrated computational efficiency with significantly lower training time compared to previous studies.
Read Full Article
14 Likes
Arxiv
262
Image Credit: Arxiv
Enhanced Whole Page Optimization via Mixed-Grained Reward Mechanism-Adapted Language Models
- Whole Page Optimization (WPO) is crucial for improving user experience by optimizing search and recommendation results.
- Pre-trained Large Language Models (LLMs) are effective in generating relevant content, but fine-tuning them for complex tasks like WPO is challenging.
- This study introduces PageLLM, a reward-based fine-tuning approach for LLMs using user feedback as supervision.
- PageLLM utilizes a mixed-grained reward mechanism integrating page-level and item-level rewards to optimize presentation.
- Page-level reward assesses quality and coherence, while item-level reward focuses on accuracy and relevance of recommendations.
- User feedback is noisy and less precise compared to manually labeled datasets, posing a challenge that PageLLM addresses.
- PageLLM was tested on public and industrial datasets, surpassing baselines and showing a 0.44% GMV increase in an online A/B test.
- The dual-reward structure of PageLLM enhances both the overall quality and the individual components of WPO.
- Fine-tuning LLMs for WPO using user feedback reduces reliance on costly human-annotated data.
- PageLLM's success in real-world applications highlights its effectiveness in improving user engagement and system performance.
Read Full Article
15 Likes
Arxiv
259
Image Credit: Arxiv
LLM-ML Teaming: Integrated Symbolic Decoding and Gradient Search for Valid and Stable Generative Feature Transformation
- Feature transformation is crucial for enhancing data representation by creating new features from the original data.
- Generative AI shows promise in this area but struggles with stable and error-free output generation.
- Existing methods have limitations in ensuring both valid syntax and stable performance.
- A new framework is proposed that combines LLMs' symbolic generation with ML's gradient optimization.
- The proposed framework includes steps such as generating high-quality samples, embedding and searching for better feature transformations, distilling knowledge between LLMs, and combining ML and LLM probabilities for stable generation.
- Experiments on various datasets show that this framework can improve downstream performance by 5% and reduce error cases by nearly half.
- The results highlight the effectiveness and robustness of the collaborative approach.
- The study also unveils interesting insights into LLMs' ability to understand original data.
Read Full Article
15 Likes
Arxiv
251
Image Credit: Arxiv
Spiking Neural Models for Decision-Making Tasks with Learning
- Decision-making tasks in cognition are commonly modeled using Drift Diffusion Models (DDMs) and Poisson counter model.
- These models lack a learning mechanism and are limited to tasks where participants have prior knowledge of the categories.
- A proposal for a Spiking Neural Network (SNN) model for decision-making is made to bridge the gap between cognitive and biological models.
- The SNN model incorporates a learning mechanism and neuron activities are modeled by a multivariate Hawkes process.
- A coupling result between DDM and the Poisson counter model is shown, indicating similar categorizations and reaction times.
- The DDM can be approximated by spiking Poisson neurons.
- A particular DDM with correlated noise can be derived from a Hawkes network of spiking neurons governed by a local learning rule.
- An online categorization task was designed to evaluate the model predictions.
- The work aims to integrate biologically relevant neural mechanisms into cognitive models for a deeper understanding of neural activity and behavior.
Read Full Article
15 Likes
Arxiv
160
Image Credit: Arxiv
Integrating Asynchronous AdaBoost into Federated Learning: Five Real World Applications
- This paper introduces an enhanced asynchronous AdaBoost framework for federated learning (FL) with applications in computer vision, blockchain, mobile personalization, IoT anomaly detection, and healthcare diagnostics.
- The algorithm incorporates adaptive communication scheduling and delayed weight compensation to reduce synchronization frequency and communication overhead while maintaining or enhancing model accuracy.
- The study evaluates improvements in communication efficiency, scalability, convergence, and robustness in each domain through comparative metrics such as training time, communication overhead, convergence iterations, and classification accuracy.
- Empirical results demonstrate notable reductions in training time (20-35%) and communication overhead (30-40%) compared to baseline AdaBoost, with faster convergence in boosting rounds.
- The research provides mathematical formulations for adaptive scheduling and error-driven synchronization thresholds, illustrating enhanced efficiency and robustness in various FL scenarios.
Read Full Article
9 Likes
Arxiv
152
Image Credit: Arxiv
CUDA-LLM: LLMs Can Write Efficient CUDA Kernels
- Large Language Models (LLMs) are being utilized for efficient CUDA kernel generation for GPUs.
- The challenge lies in creating deeply hardware-specific, performance-critical code for massively parallel GPUs.
- A novel framework called Feature Search and Reinforcement (FSR) is introduced for CUDA program optimization.
- FSR optimizes compilation, functional correctness, and runtime performance of CUDA programs.
- The framework is validated through extensive test cases and actual GPU kernel execution latency measurements.
- LLMs using FSR can generate syntactically and semantically correct CUDA code while refining it for efficiency.
- Evaluation of FSR on various CUDA kernels shows correctness rates and significantly improved execution speeds.
- Automatically generated kernels outperform human-written code by up to 179 times in execution speeds.
- The results indicate the potential of combining LLMs with performance reinforcement for GPU programming.
- LLMs empowered with FSR can streamline GPU programming for architecture-aware and performance-sensitive applications.
Read Full Article
9 Likes
Arxiv
137
Image Credit: Arxiv
Intra-Trajectory Consistency for Reward Modeling
- Reward models play a crucial role in enhancing large language models, especially in reinforcement learning from human feedback or inference-time verification.
- Current reward modeling methods primarily rely on overall response scores for learning outcome rewards, which limits generalization on unseen responses.
- A new approach is proposed in this paper that utilizes generation probabilities to establish intra-trajectory consistency in the response trajectory.
- This approach allows for fine-grained signals to propagate across processes, aiding in reward learning.
- An intra-trajectory consistency regularization is developed to ensure consistent rewards between adjacent processes with higher next-token generation probabilities.
- The proposed regularization is applied to an advanced outcome reward model, leading to improved performance on RewardBench.
- The reward model trained with the new regularization demonstrates better DPO-aligned policies and achieves improved best-of-N (BON) inference-time verification results.
- The code for the proposed approach is available at https://github.com/chaoyang101/ICRM.
Read Full Article
8 Likes
For uninterrupted reading, download the app