A naukri.com initiative
ML News
Towards Data Science
196

The Invisible Revolution: How Vectors Are (Re)defining Business Success
- Vectors play a crucial role in modern business success, offering a dynamic, multidimensional view of underlying connections and patterns.
- Understanding vector thinking is essential for decision-making, customer engagement, and data protection in today's data-focused world.
- Vectors represent a different concept of relationships, enabling accurate measurement in a multidimensional space for tasks like fraud detection and customer analysis.
- Using vector-based computing, businesses can analyze patterns and anomalies, leading to more precise decision-making and personalized customer experiences.
- Vector-based systems transform complex data into actionable insights, changing how businesses operate and make strategic decisions.
- Cosine similarity and Euclidean distance are key metrics that influence the performance and outcomes of recommendation engines, fraud detection systems, and more.
- Real-world applications, such as healthcare early detection systems using vector representations, showcase the practical impact of leveraging vectors for complex data analysis.
- Leaders who grasp vector concepts can make informed decisions, drive innovation in personalization and fraud detection, and position their businesses for success in an AI-driven landscape.
- Adopting vector-based thinking is crucial for businesses to stay competitive and thrive in an age where data and AI innovations define success.
- Embracing vectors as a fundamental tool for data literacy and decision-making can propel businesses forward in the evolving landscape of AI technology.
- Vectors are at the core of the invisible revolution reshaping business strategies, and mastering their principles is vital for leaders to navigate and lead in the data-driven future.
Read Full Article
10 Likes
Medium
290

Image Credit: Medium
From Sensor Data to Smart Decisions: How We Built a Contactless Security System with AI
- During Deep Blue Season 6, a team of students tackled the urgent need to automate residential society gate security.
- The team designed an AI-powered contactless gate system using facial recognition, sensor data, and automation logic.
- Initially designed for building entry, the system was moved to the main gate to accommodate the varied ways people enter societies.
- The system had two parallel flows for walk-ins and vehicles, each with its own logic and triggers.
- The core components used in the system included Python for logic, OpenCV for face detection, and IR temperature sensors for monitoring.
- Challenges like face recognition with masks and gate triggering for vehicles were addressed through training and design adjustments.
- Real-world behaviors, such as drivers lowering windows for interaction, were considered to ensure smooth vehicle entry.
- Feedback mechanisms and defined fallback flows were implemented for every possible failure scenario.
- Lessons learned included the importance of user experience design and interaction with real-world users.
- The team presented a fully working prototype to mentors, showcasing real-time face recognition and gate control.
Read Full Article
17 Likes
Amazon
105

Image Credit: Amazon
Reduce ML training costs with Amazon SageMaker HyperPod
- Training large-scale frontier models is computationally intensive and can take weeks to months to complete a single job, with potential hardware failures causing significant disruptions.
- High instance failure rates during distributed training highlight the challenges faced during large-scale model training.
- As cluster sizes grow, the likelihood of hardware failures increases, leading to decreased mean time between failures (MTBF).
- Amazon SageMaker HyperPod is a resilient solution that automates hardware issue detection and replacement, minimizing downtime and reducing training costs.
- By utilizing SageMaker HyperPod, manual interventions for hardware failures, root cause analysis, and system recovery are minimized, enhancing system reliability.
- HyperPod's automated mechanisms result in faster failure detection, shorter replacement times, and rapid job resumption, contributing to reduced total training time.
- SageMaker HyperPod's benefits are significant for large clusters, offering health monitoring agents, ML tool integrations, and insights into cluster performance for efficient model development.
- Empirical data shows that HyperPod reduces total training time by up to 32% in a 256-instance cluster with a 0.05% failure rate, translating to substantial cost savings.
- Automating hardware issue detection and resolution with SageMaker HyperPod enables faster time-to-market, leading to more effective innovation delivery.
- By addressing the reliability challenges of large-scale model training, HyperPod allows ML teams to focus on model innovation, streamlining infrastructure management.
- SageMaker HyperPod's contribution to reducing downtime and optimizing resource utilization makes it a valuable solution for organizations engaged in frontier model training.
Read Full Article
6 Likes
Towards Data Science
187
How to Measure Real Model Accuracy When Labels Are Noisy
- Ground truth is never perfect, with errors in measurements and human annotations, raising concerns on evaluating models using imperfect labels.
- Exploring methods to estimate a model's 'true' accuracy when labels are noisy is essential.
- Errors in both model predictions and ground truth labels can mislead accuracy measurements.
- The true accuracy of a model can vary based on error correlations between the model and ground truth labels.
- Indications show that the model's true accuracy depends on the overlap of errors with ground truth errors.
- If errors are uncorrelated, a probabilistic estimate formula can help derive a more precise true accuracy.
- In practices where errors may be correlated, the true accuracy tends to lean towards the lower bound.
- Understanding the difference between measured and true accuracy is crucial for accurate model evaluation.
- Targeted error analysis and multiple independent annotations are recommended for handling noisy labels in model evaluation.
- In summary, the range of true accuracy depends on ground truth error rates, with considerations for error correlations in real-world scenarios.
Read Full Article
9 Likes
Siliconangle
37

Image Credit: Siliconangle
Insurance technology startup Ominimo raises €10M in funding
- Insurance technology startup Ominimo has raised €10 million in funding from Zurich Insurance Group Ltd.
- Zurich Insurance took a 5% stake in Ominimo, valuing the startup at €200 million.
- Ominimo uses AI to generate quotes and streamline the sign-up process for customers.
- The funding will be used to expand into new markets and offer property insurance plans.
Read Full Article
2 Likes
Towards Data Science
404
Ivory Tower Notes: The Problem
- The concept of starting a Machine Learning or AI journey with defining the correct problem is crucial, as emphasized in the article Ivory Tower Notes: The Problem.
- The term 'Ivory Tower' refers to being isolated from practical realities, often seen in academia where researchers focus on theoretical pursuits.
- The article highlights the importance of understanding the business problem thoroughly before attempting to solve it in the data science or AI field.
- It stresses the significance of formulating good, concrete, and tractable questions that guide the project towards the right solutions.
- The process depicted involves starting with the end goal in mind and planning backward to navigate data science projects effectively.
- Defining the problem accurately lays the foundation for subsequent steps like data collection, modeling, and evaluation.
- The narrative emphasizes the need to ask iterative and insightful questions to understand the data requirements and the core problem at hand.
- By focusing on good questions and avoiding vague or unrealistic ones, data scientists can ensure they are on the right track towards solving the correct problem.
- The article concludes with a reminder from Einstein on the importance of spending time defining the problem before attempting to solve it.
- The piece offers valuable insights on the essential role of problem definition and question formulation in successful data science projects.
Read Full Article
23 Likes
Medium
33

Image Credit: Medium
Nail Your Data Science Interview: Day 5 — Neural Networks Fundamentals
- Neural networks consist of interconnected nodes organized in layers, including hidden layers, output layer, weights, biases, and activation functions.
- Activation functions like Sigmoid, Tanh, ReLU, Leaky ReLU, ELU, and Softmax introduce non-linearity in neural networks.
- Backpropagation is crucial for neural networks to learn efficiently by calculating gradients and updating parameters based on errors.
- The vanishing/exploding gradient problem in deep networks can be addressed through techniques like weight initialization, batch normalization, and LSTM/GRU.
- CNNs, RNNs, and Transformers are specialized architectures for different data types such as images, sequential data, and text data, each suited to specific tasks.
- Neural network optimizers like SGD, Adam, RMSprop, and AdaGrad adjust parameters to minimize loss, each with trade-offs in convergence and generalization.
- Proper weight initialization is essential to prevent vanishing/exploding gradients and optimize network training using strategies like Xavier, He, and LSUV.
- Batch normalization normalizes layer inputs, reducing internal covariate shift, improving training speed, and aiding convergence in deep networks.
- Combatting overfitting in neural networks involves data augmentation, dropout, early stopping, and regularization techniques to improve generalization.
- Embeddings in neural networks are low-dimensional vector representations of categorical variables that capture semantic relationships and facilitate transferable knowledge.
Read Full Article
2 Likes
Medium
358

Image Credit: Medium
My Journey from the Left to the Right
- The author shares their journey of transitioning from the left to the right.
- They initially started by consuming a lot of content, but realized the need to take action.
- They experimented with different models and techniques, such as BIDIRECTIONAL LSTMs and BERT.
- After trying various approaches and methods, their Kaggle score improved and the model now detects all labels.
Read Full Article
21 Likes
Amazon
396
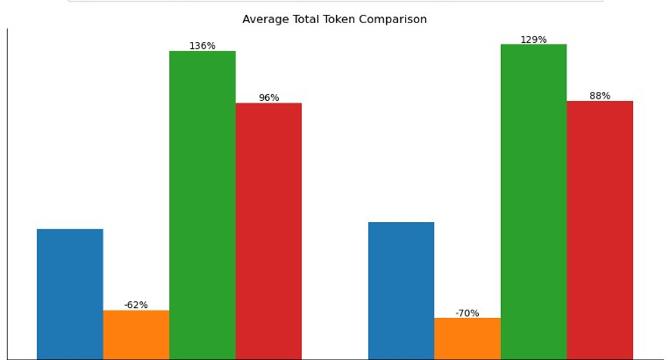
Image Credit: Amazon
Model customization, RAG, or both: A case study with Amazon Nova
- Businesses and developers face a critical choice between model customization and Retrieval Augmented Generation (RAG) for optimizing language models, with clear guidelines provided in the discussion.
- Amazon Nova models introduce advancements in AI, and the post compares model customization and RAG using these models, offering insights into their effectiveness.
- RAG enhances pre-trained models by accessing external data, while model customization adapts pre-trained models for specific tasks or domains.
- RAG is suitable for dynamic data needs, domain-specific insights, scalability, multimodal data retrieval, and secure data compliance.
- Fine-tuning excels in precise customization, high accuracy, low latency, static datasets, and cost-efficient scaling for specific tasks.
- Amazon Nova includes models optimized for accuracy, speed, and multimodal capabilities, offering cost-effective solutions trained in over 200 languages.
- The evaluation framework compared RAG and fine-tuning using Amazon Nova models, highlighting response quality improvements and latency reductions.
- Fine-tuning and RAG both enhanced response quality significantly, with combined approaches showing the highest improvement, particularly for smaller models.
- Both methods reduced response latency compared to base models, with fine-tuning offering improved tone alignment and reduced total tokens.
- Model customization can improve style, tone, and performance, offering advantages in cases where RAG may not be straightforward, like sentiment analysis.
- Authors from the AWS Generative AI Innovation Center provide expertise in data science, generative AI, and model customization for varied use cases.
Read Full Article
23 Likes
Amazon
168
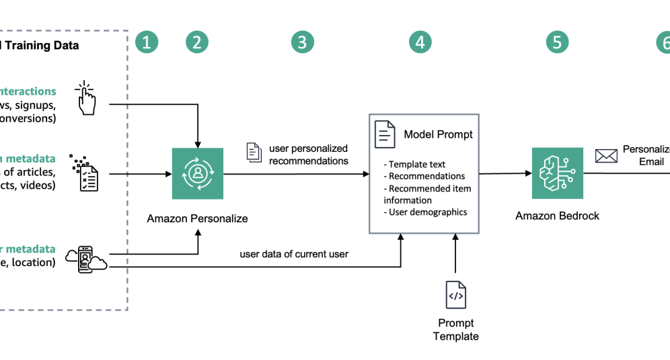
Image Credit: Amazon
Generate user-personalized communication with Amazon Personalize and Amazon Bedrock
- Businesses are utilizing AI and generative models to enhance productivity and provide personalized outbound communication.
- Amazon Personalize and Amazon Bedrock can be used for generating user-personalized recommendations and communication.
- Amazon Personalize helps create personalized recommendations for customers across various platforms.
- Amazon Bedrock offers foundational models and features for building generative AI applications securely.
- The process involves importing data into Amazon Personalize, training a recommender, and extracting recommendations.
- Amazon Bedrock is used to combine user demographic data with recommended movies for personalized outreach.
- A workflow diagram shows how Amazon Personalize and Amazon Bedrock collaborate for personalized outreach messages.
- Prerequisites include creating dataset groups, importing interaction and item data, and training a recommender.
- Amazon Personalize is used to get personal recommendations based on trained models and metadata columns.
- Amazon Bedrock is employed to generate personalized marketing emails with recommended movies and user demographics.
Read Full Article
10 Likes
Amazon
392
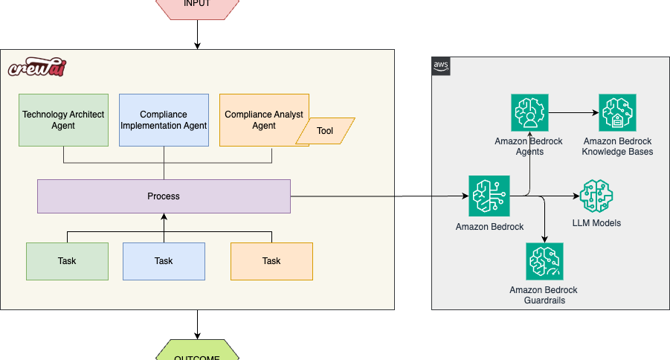
Image Credit: Amazon
Automating regulatory compliance: A multi-agent solution using Amazon Bedrock and CrewAI
- Financial institutions are facing complex regulatory challenges, leading to the need for efficient compliance mechanisms.
- AI solutions using Amazon Bedrock and CrewAI offer automation for compliance processes across industries.
- The integration of Amazon Bedrock Knowledge Bases and CrewAI enables intelligent systems for compliance management.
- The system employs specialized AI agents like compliance analyst, compliance specialist, and enterprise architect for streamlined compliance.
- CrewAI framework orchestrates agent collaboration, task management, and process execution for automation.
- Amazon Bedrock provides RAG technique for AI agents to access domain-specific data and comply with evolving regulations.
- The solution demonstrates how to build agents, define tasks, and run compliance automation using CrewAI and Amazon Bedrock.
- Amazon Bedrock Agents support multi-agent collaboration and security features for generative AI applications.
- The solution combines knowledge bases, guardrails, and CrewAI tools for an efficient compliance automation system.
- This approach showcases how AI can enhance compliance processes in highly regulated industries.
Read Full Article
23 Likes
Amazon
0

Image Credit: Amazon
Pixtral Large is now available in Amazon Bedrock
- Mistral AI’s Pixtral Large foundation model (FM) is now generally available in Amazon Bedrock, offering a frontier-class multimodal model for generative AI on AWS, uniquely managed as a serverless model.
- Pixtral Large integrates a 123-billion-parameter multimodal decoder with a 1-billion-parameter vision encoder, enabling seamless processing of visual and textual data with exceptional language-processing capabilities.
- Key capabilities of Pixtral Large include multilingual text analysis, chart and data visualization interpretation, and general visual analysis with a vast context window of 128,000 tokens for comprehensive understanding.
- Pixtral Large supports tasks like interpreting written information across languages, analyzing visual data representations, and providing contextual image understanding, enhancing data-driven decision-making.
- The model is available in specific AWS regions and supports cross-region inference, identified by its model ID and context window details.
- To start using Pixtral Large in Amazon Bedrock, users can request model access, select the model through the console, and access it via API using code examples for practical implementation.
- Pixtral Large demonstrates competency in generating SQL code from entities, extracting organization hierarchy to structured text, and reasoning over charts and graphs for insightful data analysis.
- The model’s ability to interpret and produce structured data enables diverse use cases in document understanding, logical reasoning, image comparison, and more, enhancing productivity across enterprise applications.
- Noteworthy contributors to the Pixtral Large implementation and deployment include Deepesh Dhapola, Andre Boaventura, Preston Tuggle, Shane Rai, Ankit Agarwal, Niithiyn Vijeaswaran, and Aris Tsakpinis.
- Overall, Pixtral Large on Amazon Bedrock empowers users with advanced AI capabilities for various applications like ecommerce, marketing, and financial services, showcasing its transformative potential within enterprises.
Read Full Article
Like
Medium
223

Image Credit: Medium
5 Python Concepts I Wish I Understood Before My First Project
- Virtual environments are necessary for maintaining clean Python setups and avoiding dependency hell.
- Using pip freeze to generate requirements.txt can simplify managing dependencies in the future.
- Writing functions is not just about reusability, but also about making the code logical and maintainable.
- Breaking down code early on helps readability and future understanding, especially during challenging times.
Read Full Article
13 Likes
Medium
42

Image Credit: Medium
Testing What Learns: The Role of Software QA in Foundation Model-Based Recommendation Systems
- User behavior can be tokenized, introducing complexity to test model-based recommendation systems.
- Netflix addresses the 'cold start' problem by using a hybrid representation and dynamically prioritizing user interactions.
- Software QA needs to shift from verifying outputs to interrogating learned behaviors.
- QA professionals will be at the forefront of complex, dynamic systems that redefine quality standards.
Read Full Article
2 Likes
Medium
50

Image Credit: Medium
Implementing CNN In PyTorch (Testing On MNIST — 99.26% Test Accuracy)
- Importing necessary Python libraries like numpy, torch, and torchvision for implementing CNN on the MNIST dataset in PyTorch.
- Using PyTorch's MNIST class to load training and test images efficiently, with automatic downloading and organization.
- Understanding the tuple structure of data samples in PyTorch's MNIST dataset and the importance of image to tensor transformation.
- Visualizing random samples from the training set to gain insights into the handwriting styles and variation in digits.
- Preprocessing images by transforming them into tensors, essential for neural network processing.
- Creating a validation split and restructuring data for efficient training using PyTorch functions.
- Building a CNN architecture using PyTorch's Sequential container, stacking layers like convolution, batch normalization, and activation functions.
- Verifying the model architecture and setting up device-agnostic code to enable GPU acceleration if available.
- Selecting loss function, optimizer, and performance metrics, optimizing data handling for efficient training.
- Training the model with key phases like forward pass, backward pass, and validation, tracking metrics, and achieving near-perfect accuracy.
Read Full Article
3 Likes
For uninterrupted reading, download the app