A naukri.com initiative
Big Data News
Siliconangle
438

Image Credit: Siliconangle
Databricks buys feature engineering startup Fennel to enhance AI model development
- Databricks acquires feature engineering startup Fennel AI to enhance AI model development.
- Fennel AI has a modern, incremental compute engine that supports the development of more refined data pipelines.
- Feature engineering is crucial for AI development as it improves the quality of features used in training AI models.
- Databricks aims to simplify the challenges of feature engineering by integrating Fennel's platform into its Data Intelligence Platform.
Read Full Article
25 Likes
Amazon
135

Image Credit: Amazon
Accelerate your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse
- Amazon SageMaker Lakehouse integrates with Amazon S3 Tables, offering unified access to S3 Tables, Redshift data warehouses, and other data sources for analytics and querying.
- Organizations are increasingly data-driven and require faster access to vast data across various sources for analytics and AI/ML use cases.
- A retail company example demonstrates the need for managing diverse data sources and volumes, leading to the adoption of a data lake using Apache Iceberg.
- SageMaker Lakehouse provides centralized data management across different data sources and analytics services, simplifying access and permissions.
- The article guides users through setting up analytics services with SageMaker Lakehouse, enabling data unification and collaboration for insights.
- High-level steps include creating table buckets, publishing Redshift data to the Data Catalog, and setting up SageMaker Unified Studio for projects.
- The solution architecture focuses on Example Retail Corp, illustrating how data from customer touchpoints can be consolidated and analyzed for business insights.
- Users like data analysts, BI analysts, and data engineers benefit from integrated access to data lakes and warehouses for analytics, reporting, and modeling tasks.
- The process involves creating S3 Tables, onboarding Redshift tables, setting up SageMaker projects, granting access permissions, and verifying data access in SageMaker Unified Studio.
- By unifying data access and tools, SageMaker Lakehouse enables efficient data analysis, querying, and modeling across multiple data sources with fine-grained control.
Read Full Article
8 Likes
Precisely
380

Image Credit: Precisely
What You Need to Know to Stay Compliant with Top DORA Regulations
- Financial institutions must adhere to strict cybersecurity standards set by DORA, including managing IT risks, incident reporting, and protecting sensitive data.
- Automation through a unified CCM platform can simplify compliance processes, streamline audits, and accelerate reporting for financial organizations.
- Proactive measures like disaster recovery, single-source archiving, and structured approval workflows are crucial to ensure compliance and reduce disruptions.
- DORA, the Digital Operational Resilience Act, aims to enhance cyber resilience in the financial sector across Europe by imposing mandatory requirements.
- DORA emphasizes the protection of financial stability, minimization of IT and operational risks, and ensuring compliance for financial institutions.
- Specific measures required for DORA compliance include ICT risk management, incident reporting, and data security and compliance for organizations and ICT service providers.
- EngageOne RapidCX from Precisely offers solutions like disaster recovery capabilities, audit trails, and security controls to assist in meeting DORA requirements effectively.
- Failure to comply with DORA can lead to regulatory fines, operational downtime, data breaches, and legal risks for financial institutions.
- Preparing for DORA involves implementing capabilities like audit trails for all changes, a single-source archive, and built-in disaster recovery measures.
- EngageOne RapidCX provides a unified CCM platform to centralize communication management, automate compliance processes, and prepare for audits to ensure enhanced compliance with DORA and evolving regulations.
Read Full Article
22 Likes
Siliconangle
117

Image Credit: Siliconangle
Monte Carlo puts AI agents to work on data reliability
- Monte Carlo Data Inc. has launched Observability Agents, AI agents aimed at automating monitoring and speeding up incident response times.
- The suite includes two AI agents - a monitoring agent for data quality thresholds and a troubleshooting agent for investigating and suggesting fixes for data issues.
- These AI agents aim to ensure data reliability in organizations by providing automated monitoring and troubleshooting capabilities.
- Monte Carlo's agents go beyond mere recommendations, utilizing a network of language models and sub-agents for a comprehensive view of data estates.
- The monitoring agent saves time by automating the creation and deployment of rules for monitoring data quality, identifying patterns missed by humans.
- It can prioritize critical alerts and has shown a 60% acceptance rate, improving monitoring deployment efficiency by over 30%.
- The troubleshooting agent aims to reduce investigation time for data quality issues by exploring possible causes across data tables, reducing resolution time by 80%.
- Monte Carlo plans to enhance the capabilities of its AI agents in the future to further assist data teams in ensuring data quality.
- The company's approach with AI agents aims to provide better data quality for analytics-driven business decisions in today's data-centric economy.
- AI agents like those from Monte Carlo are designed to automate mundane tasks and empower human workers to focus on higher-value work.
Read Full Article
7 Likes
Bigdataanalyticsnews
167

Image Credit: Bigdataanalyticsnews
Exploring the Architecture of Large Language Models
- Large Language Models (LLMs) are essential in AI, powered by transformer architecture and trained on vast textual data to perform various tasks in natural language processing.
- Understanding LLM architecture is crucial for optimizing problem-solving, prompt engineering, performance, security, ethical use, and staying competitive in the job market.
- Transformers, with attention mechanisms and parallel processing, form the core architecture of LLMs, enhancing their ability to understand and generate languages efficiently.
- Scaling laws play a vital role in improving LLM performance with larger models, more training data, and compute resources, while considering optimal scaling for efficiency.
- Applications of LLMs range from customer support, content creation, and healthcare to education, legal services, and translation, showcasing their diverse real-world implications.
- The future of LLMs includes more specialized models, multimodal capabilities, human-AI collaboration, efficiency improvements, responsible AI practices, and regulatory governance.
- Learning LLM architecture in an AI course like the one offered at the Boston Institute of Analytics provides a competitive edge in the job market, hands-on learning, and access to expert faculty and industry networks.
- Courses at institutions like BIA prepare individuals to understand the technology behind LLMs, gain relevance in the evolving AI field, and be part of the AI innovation and talent demand.
- Ultimately, the growth of LLMs in AI signifies the need for skilled professionals who can innovate and work on advanced models to meet the increasing demands for AI-assisted solutions in various industries.
Read Full Article
10 Likes
Zazz
46

Image Credit: Zazz
Data Engineer vs Data Scientist: Choosing the Right Expert for Your Team
- Data engineers and data scientists play crucial roles in leveraging data for actionable insights within organizations.
- Data engineers focus on building and maintaining data infrastructure, while data scientists extract insights using statistical and machine learning techniques.
- Data engineers design data systems, optimize performance, and ensure clean data for analysis, while data scientists interpret data to drive decision-making and forecast trends.
- Data engineers specialize in database management, ETL processes, and big data frameworks, while data scientists focus on data exploration, statistical analysis, and machine learning.
- Both roles require collaboration, with data engineers working on infrastructure and data quality, and data scientists communicating insights to stakeholders.
- Data engineers typically have technical backgrounds in fields like Computer Science, while data scientists often come from analytical disciplines like Statistics or Data Science.
- Use cases for data engineers include building data warehouses, developing ETL pipelines, and ensuring data governance, while data scientists focus on predictive analytics and customer segmentation.
- Top challenges for data engineers include ensuring data quality, scalability, system integration, and compliance, while data scientists face issues like unclean data, lack of domain knowledge, model deployment, and balancing technical rigor with business needs.
- Businesses benefit most from a combination of data engineers and data scientists to ensure a robust data infrastructure and actionable insights for informed decision-making.
- Individuals interested in these roles should consider the required skills, educational backgrounds, and the collaborative nature of the work involved.
Read Full Article
2 Likes
Siliconangle
390

Image Credit: Siliconangle
Bauplan raises $7.5M to automate data infrastructure as code for AI software developers
- Bauplan Inc. has raised $7.5 million in seed funding to automate big data infrastructure for software developers.
- The round was led by Innovation Endeavors and included angel investors such as Wes McKinney, Aditya Agarwal, and Chris Re.
- Bauplan offers a 'serverless runtime' for processing large datasets using Python commands, simplifying AI app development.
- Developers can create data pipelines and applications without needing to worry about manual infrastructure tasks.
- Bauplan aims to provide a code-first approach for data infrastructure, making it accessible to developers without specialized knowledge.
- The platform is designed to integrate with continuous development workflows and is based on Python.
- Bauplan's goal is to enable developers to focus on building applications by removing the complexity of data infrastructure setup.
- Enterprise adoption of AI and data analytics is driving the need for disciplined data pipeline engineering.
- Bauplan's platform targets medium-to-large enterprises in industries like financial services, healthcare, and media.
- Early adopters like MFE-MediaForEurope have found relief from data infrastructure challenges with Bauplan's solution.
Read Full Article
23 Likes
Dzone
217

Image Credit: Dzone
Securing Parquet Files: Vulnerabilities, Mitigations, and Validation
- Parquet files are widely used for columnar data storage in big data ecosystems, by frameworks like Apache Spark and Hadoop, due to high-performance compression and effective data storage.
- Recent examples such as CVE-2025-0851 and CVE-2022-42003 highlight security risks stemming from vulnerabilities in open-source Java libraries.
- Careful dependency management, updates, and security audits are crucial for open-source libraries to avoid vulnerabilities in systems.
- A critical vulnerability (CVSS 10.0) was reported in the Parquet-Avro module due to deserialization of untrusted schemas, enabling arbitrary code execution.
- An attack scenario exploiting this vulnerability involves crafting a malicious Parquet file with corrupted Avro schema, delivering it to the victim system, and executing the exploit payload during file processing.
- Mitigation steps include conducting a dependency audit, validating file sources, auditing and monitoring logs, restricting access and permissions, and securing file sources.
- By upgrading to patched versions, enforcing schema validation, monitoring logs, implementing RBAC and network segmentation, and processing files from trusted sources only, organizations can enhance the security of data pipelines.
- Ensuring adherence to industry standards and robust security measures is essential for safeguarding data pipelines and protecting sensitive information in distributed systems.
Read Full Article
13 Likes
Precisely
167

Image Credit: Precisely
Mastering AI Data Observability: Top Trends and Best Practices for Data Leaders
- Observability is crucial for trusted AI, but many organizations lack structured programs and tools for effectiveness.
- U.S. organizations exhibit higher maturity in observability and trust in AI compared to Europe.
- Data leaders need to address skills gaps, invest in tools, and align governance practices for AI success.
- Only 59% of organizations trust their AI/ML model inputs and outputs, highlighting a major concern.
- It is essential for data leaders to establish robust observability practices for quality inputs and transparent outputs.
- Challenges like skills gap, AI data trust issues, tooling gaps, and observability maturity need to be overcome for AI success.
- North America leads in AI observability maturity, with Europe lagging behind in formalized programs.
- AI observability involves monitoring data quality, pipelines, and AI models for accurate insights.
- Adopting dedicated AI observability tools, addressing skill gaps, and ensuring trust in AI outputs are crucial steps.
- Establishing metrics for observability success, expanding observability beyond structured data, and fostering AI trust are key best practices.
Read Full Article
10 Likes
Amazon
282

Image Credit: Amazon
Build unified pipelines spanning multiple AWS accounts and Regions with Amazon MWAA
- Organizations face challenges in orchestrating data and analytics workloads across multiple AWS accounts and Regions, but Amazon MWAA can help streamline this process.
- Amazon MWAA is a managed orchestration service for Apache Airflow, allowing users to create workflows without managing underlying infrastructure.
- A scenario involving data processing and machine learning teams in different AWS Regions demonstrates how to use Amazon MWAA for centralized orchestration.
- Architecture involves a centralized hub in one account orchestrating data pipelines in different accounts and Regions for seamless data flow.
- Setting up prerequisites involves creating roles, S3 buckets, and templates in multiple AWS accounts to enable cross-account data processing.
- Cross-account and cross-Region workflow setup includes IAM roles, Airflow connections, DAG implementation, and SageMaker operations for data processing and machine learning.
- Best practices for integration include secrets management, networking solutions, IAM role management, error handling, and managing Python dependencies.
- To clean up, all created resources should be removed to avoid future charges and ensure proper termination of services.
- The article concludes by emphasizing the benefits of using cross-account orchestration for complex data workflows and encourages readers to test the approach.
- Authors of the article include AWS technical experts passionate about data and analytics, providing valuable insights and guidance on implementing advanced AWS solutions.
Read Full Article
17 Likes
Amazon
118

Image Credit: Amazon
Integrate ThoughtSpot with Amazon Redshift using AWS IAM Identity Center
- Amazon Redshift is a popular cloud data warehouse used by many customers for data processing and analytics workloads.
- The collaboration between Amazon Redshift and ThoughtSpot facilitates transforming raw data into actionable insights efficiently.
- Integration of AWS IAM Identity Center with ThoughtSpot enables secure data access and streamlined authentication workflows.
- Prior to this integration, ThoughtSpot users lacked native connectivity to integrate Amazon Redshift with identity providers for unified governance.
- The IAM Identity Center integration allows ThoughtSpot users to connect natively to Amazon Redshift, enhancing data access management and security.
- Organizations can benefit from single sign-on capabilities, trusted identity propagation, and role-based access control features with this integration.
- The integration offers centralized user management, automatic synchronization of access permissions, and granular access control on catalog resources.
- The solution provides comprehensive audit trails by logging end-user identities in Amazon Redshift and AWS CloudTrail for visibility into data access patterns.
- The article guides readers on setting up ThoughtSpot integration with Amazon Redshift using IAM Identity Center for a secure and streamlined analytics environment.
- AWS IAM Identity Center must be set up with Amazon Redshift integration, and prerequisites include a ThoughtSpot paid account with admin access and an active IdP account like Okta or Microsoft EntraID.
- Detailed steps are provided for setting up an OIDC application with Okta or EntraID, creating a TTI in IAM Identity Center, configuring client connections and TTIs in Amazon Redshift, and federating with Amazon Redshift from ThoughtSpot using IAM Identity Center.
Read Full Article
7 Likes
Siliconangle
341
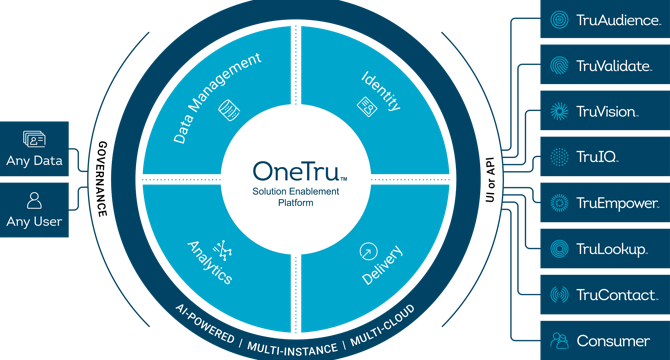
Image Credit: Siliconangle
TransUnion caps massive data migration project with new analytics and security services
- Credit reporting company TransUnion caps its massive data migration project with the completion of its OneTru platform, which has provided multiple benefits internally and for its business customers.
- TransUnion's alternative lending bureau uses OneTru to introduce new credit risk products, while marketers utilize the TruAudience line of products for identity-driven marketing.
- TransUnion's TruValidate fraud prevention service has improved fraud capture rates and reduced false positives, resulting in increased fraud capture rates for financial institutions.
- TransUnion has seen over a 50% productivity boost from migrating legacy products to run on top of the OneTru platform.
Read Full Article
20 Likes
Amazon
22

Image Credit: Amazon
Streamline data discovery with precise technical identifier search in Amazon SageMaker Unified Studio
- Amazon SageMaker Catalog now offers exact match search using technical identifiers, enhancing data discovery and precision.
- This feature allows users to search for assets like column names and database names with quotes for precise results.
- The update simplifies the process of finding specific technical identifiers in large datasets, improving efficiency.
- Customers, like NatWest, benefit from faster asset discovery and better metadata governance with the new search capabilities.
- Key benefits include quicker asset location, reduced false positives, accelerated productivity, and improved governance.
- Use cases span across roles like data analysts, data stewards, and data engineers, enhancing various workflows.
- The solution demo illustrates how the technical identifier search can be used to find specific data assets efficiently.
- Overall, the introduction of precise technical identifier search in SageMaker Unified Studio enhances data discovery in complex ecosystems.
- The feature caters to the needs of diverse stakeholders and aims to simplify data management and improve productivity.
- SageMaker Unified Studio continues to evolve to address the growing scale and complexity of data, offering features for actionable insights.
- Start leveraging this enhanced search capability in SageMaker Unified Studio for a better data discovery experience.
Read Full Article
1 Like
Amazon
241

Image Credit: Amazon
Process millions of observability events with Apache Flink and write directly to Prometheus
- AWS introduced a new Apache Flink connector for Prometheus, allowing data to be directly sent to Amazon Managed Service for Prometheus.
- Amazon Managed Service for Prometheus enables real-time observability without managing infrastructure, utilizing Prometheus's data model and query language.
- Observability extends beyond IT assets, including IoT devices, and metrics play a crucial role in capturing measurements from these distributed devices.
- Prometheus serves as a specialized time series database for real-time dashboards and alerting, optimized for various distributed assets, not just compute resources.
- Handling observability data at scale poses challenges like high cardinality, frequency, irregular events arrival, lack of contextual information, and deriving metrics from events.
- Preprocessing raw observability events before storing can optimize real-time dashboards and alerting by reducing frequency and cardinality.
- Apache Flink is a suitable engine for preprocessing observability events, allowing efficient enrichment, aggregation, and derivation of metrics at scale.
- The new Flink Prometheus connector seamlessly writes preprocessed data to Prometheus, eliminating the need for intermediate components and scaling horizontally.
- Example use case scenarios demonstrate how preprocessing with Flink enhances visualization and analysis of metrics for improved observability.
- The Flink Prometheus connector optimizes write throughput by parallelizing and batching writes, adhering to Prometheus Remote-Write specifications.
Read Full Article
14 Likes
Amazon
274

Image Credit: Amazon
Manage concurrent write conflicts in Apache Iceberg on the AWS Glue Data Catalog
- Apache Iceberg is a popular table format for data lakes, offering features like ACID transactions and concurrent write support.
- Implementing concurrent write handling in Iceberg tables for production environments requires careful consideration.
- Common conflict scenarios include concurrent UPDATE/DELETE, compaction vs. streaming writes, concurrent MERGE operations, and general concurrent table updates.
- Iceberg's concurrency model uses a layered architecture for managing table state and data to handle conflicts at commit time.
- Write transactions in Iceberg involve steps like reading current state, determining changes, and committing metadata files.
- Catalog commit conflicts and data update conflicts are crucial points where conflicts can occur in Iceberg transactions.
- Iceberg tables support isolation levels such as Serializable and Snapshot isolation for handling concurrent operations.
- Implementation patterns for managing catalog commit conflicts and data update conflicts involve retry mechanisms and scoping operations.
- By applying these patterns, understanding Iceberg's concurrency model, and configuring isolation levels, robust data pipelines can be built.
- Proper error handling, retry settings, and backoff strategies are essential for building resilient data pipelines with Iceberg.
Read Full Article
16 Likes
For uninterrupted reading, download the app