A naukri.com initiative
Databases
Amazon
195

Image Credit: Amazon
Transform uncompressed Amazon DocumentDB data into compressed collections using AWS DMS
- Demonstrating transition from uncompressed to compressed collections for Amazon DocumentDB using AWS DMS.
- Migration reduces storage costs, compute expenses, and improves performance in Amazon DocumentDB.
- Case study showcases challenges faced and solutions implemented during the migration process.
- Optimization tips for AWS DMS to efficiently handle data migration tasks.
- Addressing compression challenges in Amazon DocumentDB clusters for improved performance and cost savings.
Read Full Article
11 Likes
Amazon
39

Image Credit: Amazon
Introducing Amazon Keyspaces CDC streams
- Amazon Keyspaces (for Apache Cassandra) allows running workloads on AWS as a serverless database.
- The new CDC streams feature captures real-time data changes in tables.
- CDC streams enable instant tracking and response to data manipulations, unlocking new possibilities.
- You can access CDC streams for downstream use cases, providing real-time, robust data processing.
Read Full Article
2 Likes
Siliconangle
391
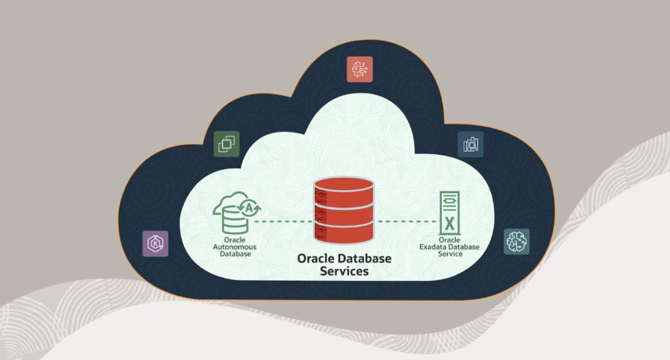
Image Credit: Siliconangle
Oracle Database@AWS launches into general availability with new features
- Oracle Corp. and Amazon Web Services Inc. have launched Oracle Database@AWS into general availability, featuring new enhancements for customers.
- The joint database offering includes the latest version of Oracle's flagship database, 23ai release, with features like AI Vector Search and performance optimizations.
- Oracle Database@AWS runs on Oracle-managed infrastructure in AWS data centers, offering features like Real Application Clusters (RAC) for high availability and access to Exadata appliances.
- The database integrates with AWS services, provides an Amazon S3 integration, and allows for automatic backups, making it easier for customers to deploy and manage Oracle databases in AWS environments.
Read Full Article
23 Likes
Hrexecutive
126

As the machine-human workforce emerges, it’s time to rethink management
- Integrating AI agents in HR to reshape workplace dynamics and management strategies.
- AI agents actively participate in hiring, onboarding, learning, and performance processes autonomously.
- Leaders must adapt to managing a hybrid workforce of humans and technology effectively.
- AI agents raise cultural, trust, accountability, and job design considerations in organizations.
Read Full Article
7 Likes
Discover more
- Programming News
- Software News
- Web Design
- Devops News
- Open Source News
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Medium
320
Why You Should Stop Using psql -W to Enter Your PostgreSQL Password
- The -W (or --password) flag in PostgreSQL, used for entering passwords, may not always ensure secure password authentication.
- Contrary to expectations, the -W flag does not always enforce password authentication, just prompts the user for a password.
- This can lead to a false sense of security, as the server might not actually require a password for authentication, potentially risking security.
- It's advised to be cautious while using the -W flag and consider alternative secure methods for password authentication in PostgreSQL.
Read Full Article
19 Likes
Dev
244

Image Credit: Dev
SQL Server Stored Procedure Design for Flexible Record Lookup
- Flexible stored procedure design using CTEs and JSON for various record lookups.
- Handles different input scenarios like patientid, dob, zip, and invoice number efficiently.
- CTEs aid in clean, modular match logic, facilitating easy maintenance and extension.
- Performance comparison provided for different approaches to decide optimal usage.
Read Full Article
14 Likes
Javacodegeeks
220
Image Credit: Javacodegeeks
Working with Sequences in H2 Database
- Sequences in databases aid in auto-generating unique primary keys like in Oracle and PostgreSQL.
- H2 database, commonly used for testing, also supports sequence generation for Java applications.
- Understanding Java H2 sequences for unique primary key generation in Spring Boot explored.
- Configuring H2 for sequence-based ID generation and using Oracle-style sequences demonstrated.
Read Full Article
13 Likes
Dev
336

Image Credit: Dev
What is SQL? A Beginner's Complete Guide
- SQL, or Structured Query Language, is used to communicate with databases efficiently.
- It is beginner-friendly, essential for data analysis, and widely used across industries.
- The language allows for creating, reading, updating, and deleting data in databases.
- SQL is crucial in web development, data science, and offers various real-world applications.
Read Full Article
20 Likes
Dev
255

Image Credit: Dev
The Cartesian Product Trap in Django ORM
- Adding additional Count() in a Django ORM queryset can lead to performance issues due to Cartesian Product trap.
- The problem arises when multiple Count() operations with distinct=True are used, leading to unnecessary JOINs and duplicated data.
- The solution involves using subqueries to avoid the Cartesian Product trap and improve query performance significantly.
- Lessons learned include testing aggregate queries with production data and being cautious with multi-branch JOINs to optimize performance.
Read Full Article
15 Likes
Mongodb
265
-2pbq5g7byq.png)
Image Credit: Mongodb
Don’t Just Build Agents, Build Memory-Augmented AI Agents
- Anthropic and Cognition explore memory management in AI agent design for reliability and capability.
- Both highlight crucial role of memory in agent performance, with Anthropic focusing on multi-agent systems.
- Insights include agent overthinking, system coordination trade-offs, and memory compression for distributed management.
- They stress the importance of robust memory architecture for next-gen intelligent agents, emphasizing 'Memory Augmented AI agents.'
- Recommendations on building sophisticated memory systems and understanding agents' behavior patterns.
Read Full Article
15 Likes
Dev
182

Image Credit: Dev
Tired of Writing SQL Just to Explore Your DB? Me too. So I Built This.
- Data Ramen is a lightweight, local-first GUI for exploring PostgreSQL and MySQL databases, aimed at simplifying common tasks without the need for SQL queries.
- Key features include the ability to connect to local or remote databases, browse tables, columns, and relationships without SQL, point-and-click data filtering, in-place row editing, and the option to use raw SQL.
- Users can try Data Ramen by installing it through npm, and accessing it through a web interface that runs locally on their machine. The tool is designed to complement existing database tools, rather than replace them.
- The creator of Data Ramen is open to feedback as the tool is still in beta, encouraging users to test it out, provide comments, report bugs, and suggest improvements for a better user experience.
Read Full Article
10 Likes
Mysql
393

Image Credit: Mysql
MySQL: Release Notes Database
- A Python project called mysql-release-notes has been created on GitHub to download MySQL release notes, parse them, and store them in a database.
- The project uses SQLAlchemy and mysqlclient to connect to the database, generates a schema, and fills it with release notes data.
- The schema follows a star pattern where each release has many issues, and each issue has encoded properties stored as property IDs.
- Sample queries can be used to extract valuable information like contributors, release dates, versions, and counts of text for different issues.
Read Full Article
23 Likes
Dev
395

Image Credit: Dev
How I Built a Hospital Patient Management System Using SQL
- The article discusses how the author built a Hospital Patient Management System using SQL to enhance their database management and querying skills.
- The project involved creating a relational database to manage patient information, departments, diagnoses, visit history, and risk assessments.
- Tools and skills used include SQL, database design, ERD, and GitHub for project hosting and version control.
- Key features of the system included primary and foreign key relationships, realistic sample data insertion, and clean SQL queries for analysis.
Read Full Article
23 Likes
Amazon
99

Image Credit: Amazon
How Aqua Security automates fast clone orchestration on Amazon Aurora at scale
- Aqua Security uses fast clones in Aurora PostgreSQL for large data export needs.
- They automate clone orchestration to maintain operational efficiency and avoid replication lag.
- Through fast clones, Aqua runs read-heavy operations at scale without impacting production.
- Automated cleanup ensures resources are optimized and costs are controlled effectively.
- By leveraging Aurora fast clones, Aqua achieves improved reliability and cost-effectiveness in operations.
Read Full Article
6 Likes
Amazon
250

Image Credit: Amazon
How TalentNeuron optimized data operations and cut costs and modernized with Amazon Aurora I/O-Optimized
- TalentNeuron partnered with AWS to modernize their data platform for efficiency and cost-effectiveness.
- Using Amazon Aurora I/O-Optimized reduced costs by 29%, improved data validation, and accelerated innovation.
- TalentNeuron's modernization journey involves decoupling original designs, exploring new data lakes, and streamlining data access.
- Adopting Aurora I/O-Optimized enabled TalentNeuron to save costs, simplify architecture, and boost accessibility.
Read Full Article
7 Likes
For uninterrupted reading, download the app