A naukri.com initiative
Databases
Mongodb
94

Image Credit: Mongodb
Agentic Workflows in Insurance Claim Processing
- Agentic AI is revolutionizing the insurance industry by enabling autonomous systems to independently perceive, reason, and act to achieve complex objectives by 2025.
- Insurers are investing in AI technologies like natural language processing and image classification to enhance claim processing efficiency, deliver personalized customer experiences, and tap into the projected $79.86 billion AI insurance market by 2032.
- AI tools help manage claim-related data efficiently, generating precise catastrophe impact assessments, expediting claim routing, preventing litigation, and minimizing financial losses through more accurate risk evaluations.
- AI agents in insurance claim processing workflows can autonomously manage accident photos, assess damage, verify insurance coverage, and create work orders for claim handlers, thereby improving process efficiency and customer satisfaction.
Read Full Article
5 Likes
Javarevisited
145
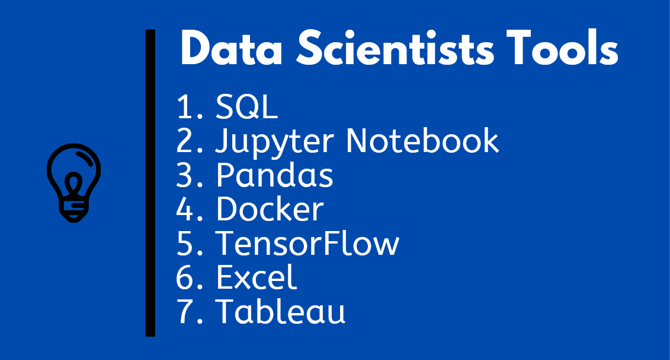
Image Credit: Javarevisited
Top 10 Tools Data Scientists and Machine Learning Developer Should Learn in 2025
- Tools and libraries play a crucial role in enhancing the efficiency of Data Scientists and Machine Learning developers.
- Data Science and Machine Learning require powerful tools for tasks such as data normalization, cleaning, visualization, and model building.
- In 2025, essential tools for Data Scientists and Machine Learning developers are being highlighted as crucial for dealing with large datasets effectively.
- Previous essential tools recommendations for Software developers, Java developers, Python developers, and Web Developers have been shared, emphasizing the importance of having the right tools in various fields.
Read Full Article
8 Likes
Dev
304

Image Credit: Dev
What is SQL and Why You Should Learn It
- SQL (Structured Query Language) is the standard language for interacting with relational databases, allowing users to manage data efficiently.
- Common use cases of SQL include data retrieval, database management, reporting & analytics, data cleaning, and integrations.
- Learning SQL is beneficial as it is beginner-friendly, works across various database systems, and is in high demand in tech jobs.
- SQL is essential for web developers, data scientists, and anyone working with structured data, providing powerful querying capabilities and vast opportunities for skill development.
Read Full Article
18 Likes
Amazon
364

Image Credit: Amazon
Achieve up to 1.7 times higher write throughput and 1.38 times better price performance with Amazon Aurora PostgreSQL on AWS Graviton4-based R8g instances
- Upgrading to Graviton4-based R8g instances with Aurora PostgreSQL-Compatible 17.4 on Aurora I/O-Optimized cluster configuration offers up to 1.7 times higher write throughput, 1.38 times better price-performance, and reduced commit latency.
- Amazon Aurora PostgreSQL-Compatible now supports AWS Graviton4-based R8g instances and PostgreSQL major version 17.4, leading to key performance improvements for Amazon Aurora I/O-Optimized configurations.
- Graviton4-based R8g instances provide improved performance, scalability, and better price-performance for memory-intensive workloads, featuring up to 192 vCPUs and 1.5 TB of memory.
- PostgreSQL 17 introduces vacuum improvements, SQL/JSON standards expansion, enhanced query performance, and greater partition management flexibility.
- Aurora PostgreSQL-Compatible enables independent scaling through a distributed storage architecture, reducing I/O operations and improving performance.
- Performance improvements on Graviton4-based R8g instances with Aurora PostgreSQL-Compatible 17.4 enhance write throughput and commit latency across various applications.
- The Aurora I/O-Optimized cluster configuration optimizes write operations, introduces smart batching, and separates critical write paths for improved performance.
- Benchmarking using HammerDB shows significant performance gains with Graviton4-based R8g instances and Aurora PostgreSQL version 17.4.
- Upgrading to Graviton4-based R8g instances from Graviton2 and PostgreSQL 15.10 to 17.4 demonstrates substantial performance improvements.
- The combined hardware and database engine version upgrade offer the most significant performance benefits with improved price performance and ratio for various workload sizes.
- The Aurora PostgreSQL-Compatible 17.4 and Graviton4-based R8g instances deliver consistent performance enhancements, enabling organizations to provide more responsive services.
Read Full Article
21 Likes
Discover more
- Programming News
- Software News
- Web Design
- Devops News
- Open Source News
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Dev
300

Image Credit: Dev
IoT monitoring with Kafka and Tinybird
- Combining Apache Kafka-compatible streaming service with Tinybird can create real-time data APIs for IoT devices.
- Kafka excels at high-throughput event streaming, while Tinybird transforms data into real-time APIs with sub-second response times.
- Utility companies utilize smart meters for real-time readings, and the Kafka + Tinybird stack provides real-time insights and APIs for customer-facing features.
- Setting up Kafka connection to Tinybird involves creating connections and data sources, simplifying the data ingestion process.
- Tinybird Local allows testing analytics backend locally before deploying to a cloud production environment.
- Creating API endpoints with Tinybird involves generating resources like endpoint configurations that accept parameters and return values.
- Deployment to cloud production environment involves setting up secrets, proper testing, and monitoring of sensors.
- Automated testing with Tinybird ensures project stability and avoids potential future issues.
- The architecture simplifies IoT data processing by using Kafka for streaming and Tinybird for creating real-time APIs.
- The system allows for scalability, version control, and easy maintenance of data processing pipelines.
Read Full Article
18 Likes
Dbi-Services
360

Image Credit: Dbi-Services
SQL Server 2025 – Standard Developer edition
- SQL Server 2025 introduces the Standard Developer edition for deploying in development, quality, and testing environments without additional licensing fees.
- The available editions in SQL Server 2025 include Express, Web, Standard, Enterprise, Standard Developer, and Enterprise Developer.
- The Standard Developer edition solves the issue of using different editions in various environments, ensuring consistency and feature alignment.
- Installation of the Standard Developer edition can be done easily through the graphical interface or by using a specific PID parameter in the .ini file.
Read Full Article
21 Likes
Dbi-Services
47

Different types of Oracle wallets
- An Oracle wallet is used to store certificates for Listeners with https protocol or as an encrypted password store for Oracle logins.
- It is an encrypted, password-protected PKCS#12 container file that can be accessed with openssl tools.
- Storing credentials in an Oracle wallet is a proprietary extension from Oracle.
- Different types of Oracle wallets include normal, auto_login, auto_login_local, and auto_login_only.
- Auto_login wallets allow for non-interactive logins without a password prompt.
- The auto_login_only wallet does not have a PKCS#12 container and allows access without a password.
- Wallet types can be determined by analyzing the content using octal dump (od) utility.
- Converting wallets between auto_login and non-auto-login types is possible with orapki commands.
- Ensure filesystem permissions are secure and restrict access to wallets for better security.
- Auto_login_only wallets are suitable for storing trusted certificates for client-connects.
Read Full Article
2 Likes
Dev
287

Image Credit: Dev
AI-Driven SQL Dataset Optimization: Best Practices & Updates for Modern Applications
- AI research in SQL relies heavily on high-quality datasets for training and evaluation purposes to enhance application capabilities in the field.
- Recent years have seen the creation of various Text2SQL datasets like Spider and BIRD-SQL, alongside the associated leaderboards for evaluation.
- New datasets introduced in 2025 include NL2SQL-Bugs dedicated to identifying semantic errors and OmniSQL, the largest cross-domain synthetic dataset.
- TINYSQL offers a structured text-to-SQL dataset for interpretability research, catering to basic to advanced query tasks for model behavior analysis.
- The article lists various datasets such as WikiSQL, Spider, SParC, CSpider, CoSQL, and more, emphasizing complexity, cross-domain challenges, and application scenarios.
- Datasets like SEDE and CHASE introduce unique challenges like complex nesting, date manipulation, and pragmatic context-specific tasks for text-to-SQL.
- The article acknowledges contributions like EHRSQL for healthcare data, BIRD-SQL for cross-domain datasets, and Archer for bilingual text-to-SQL datasets.
- Innovations like BEAVER from real enterprise data and PRACTIQ for conversational text-to-SQL datasets continue to advance the field.
- Diverse datasets like TURSpider in Turkish and synthetic_text_to_sql for high-quality synthetic samples further enrich the text-to-SQL research landscape.
- Developers are encouraged to explore these datasets, contribute to advancements, and leverage the vast resource of publicly available datasets to improve text-to-SQL models.
Read Full Article
17 Likes
Soais
399
PeopleSoft India SIG 2025- Powering the Future with Innovation and Intelligence
- The PeopleSoft India Special Interest Group (SIG) 2025 event at Oracle's Technology Hub in Bangalore showcased updates like UX enhancements and machine learning integration for the PeopleSoft community.
- Key highlights included modernized UI/UX, real-time search with Elastic Search, advanced analytics through Pivot Grid 2.0 and Kibana Dashboards, Cloud Manager enhancements, Docker & Kubernetes support, AI and machine learning features.
- PeopleTools 8.61 enhancements featured a revamped Fluid UI, mobile optimization, accessibility improvements, and AI integration.
- Overall, PeopleSoft is evolving with intelligence, agility, visualization, and connectivity, offering smart automation, DevOps tools, insightful dashboards, and secure integration with cloud and AI services.
Read Full Article
24 Likes
Soais
309
Mastering the Keystroke Method in Test Automation
- The Keystroke Method is an innovative approach to test automation that replicates user behavior by capturing and replaying keyboard inputs and mouse actions, beneficial for complex user interfaces.
- This technique involves recording and replaying keyboard and mouse inputs to simulate user actions effectively, especially in dynamic UI settings.
- Implementation steps for the Keystroke Method include selecting nodes in desktop applications, entering values in input fields using keystrokes, moving the mouse cursor with keystrokes, and assigning dynamic objects for mouse click actions.
- Tools like Worksoft Certify support the Keystroke Method, enabling realistic user experience simulation through automated testing.
Read Full Article
18 Likes
Hackernoon
284

Image Credit: Hackernoon
How to Set Up PostgreSQL with NestJS and Docker for Fast Local Development: A Quick Guide
- Setting up PostgreSQL with NestJS and Docker for fast local development is essential for new projects.
- Using Docker to run a local Postgres instance ensures minimal friction, reproducibility, and ease of access.
- Key components include Dockerfile, docker-compose.yml, .env file, sample NestJS config, and practical development commands.
- Commands like npm run db to access database shell and npm run api for the app container provide an interactive development workflow.
Read Full Article
17 Likes
Amazon
310

Image Credit: Amazon
How Amazon maintains accurate totals at scale with Amazon DynamoDB
- Amazon's Finance Technologies Tax team manages tax computation, deduction, and reporting across global jurisdictions using the DynamoDB-tiered tax withholding system.
- The system processes billions of transactions annually, requiring millisecond latency at scale and accurate tracking of individual transaction values for tax calculations.
- Challenges include handling tiered tax rates based on cumulative thresholds and maintaining data consistency across high transaction volumes.
- The solution involves API Gateway, Lambda functions, DynamoDB for tracking cumulative values, and handling error retries using Amazon SQS.
- Implementation includes atomic conditional writes for updating transaction values and audit records, optimizing throughput and minimizing conflicts.
- Performance evaluations show increased throughput with concurrency, but also highlight transient conflict trade-offs in highly concurrent scenarios.
- The DynamoDB conditional write feature allows for simplified, scalable transaction processing without the need for optimistic locking.
- Authors include Principal Solutions Architect, Principal Engineer, and Software Development Engineers from Amazon Finance Technology.
- The system's proactive handling of ConditionalCheckFailedExceptions ensures data consistency and high scalability for concurrent transactions.
- For those looking to implement similar scalable systems, leveraging DynamoDB features and concurrency control mechanisms is essential.
Read Full Article
18 Likes
Amazon
236

Image Credit: Amazon
Build an AI-powered text-to-SQL chatbot using Amazon Bedrock, Amazon MemoryDB, and Amazon RDS
- Text-to-SQL is a valuable approach leveraging large language models to automate SQL code generation for various data exploration tasks like analyzing sales data and customer feedback.
- The article discusses building an AI text-to-SQL chatbot using Amazon RDS for PostgreSQL and Amazon Bedrock, with Amazon MemoryDB for accelerated semantic caching.
- Amazon Bedrock, with foundation models from leading AI companies like AI21 Labs and Amazon, assists in generating embeddings and translating natural language prompts into SQL queries for data interaction.
- Utilizing semantic caching with Amazon MemoryDB enhances performance by reusing previously generated responses, reducing operational costs and improving scalability.
- Implementing parameterized SQL safeguards against SQL injection by separating parameter values from SQL syntax, enhancing security in user inputs.
- The article highlights Table Augmented Generation (TAG) as a method to create searchable embeddings of database metadata, providing structural context for precise SQL responses aligned with data infrastructure.
- The solution architecture includes creating a PostgreSQL database on Amazon RDS, using Streamlit for the chat application, Amazon Bedrock for SQL query generation, and leveraging AWS Lambda for interactions.
- The step-by-step guide covers prerequisites, deploying the solution with CDK, loading data to the RDS, testing the text-to-SQL chatbot application, and cleaning up resources efficiently.
- By following best practices like caching, parameterized SQL, and table augmented generation, the solution showcases enhanced SQL query accuracy and performance in diverse scenarios.
- Authors Frank Dallezotte and Archana Srinivasan provide insights into leveraging AWS services for scalable solutions and optimizing AI and ML workloads with Amazon RDS and Amazon Bedrock.
- The demonstration exhibits the capability of the text-to-SQL application to support complex JOINs across multiple tables, emphasizing its versatility and performance.
Read Full Article
14 Likes
Dbi-Services
103

Image Credit: Dbi-Services
SQLDay 2025 – Wrocław – Sessions
- The SQLDay conference in Wrocław began with a series of sessions covering cloud, DevOps, Microsoft Fabric, AI, and more.
- Morning Kick-Off: The day started with sponsors' presentation, acknowledging their support for the event.
- Key Sessions: Sessions included discussions on Composable AI, migrating SQL Server databases to Microsoft Azure, Fabric monitoring, DevOps in legacy teams, productivity solutions, and Azure SQL Managed Instance features.
- Insights: The sessions provided insights on integrating AI into enterprise architecture, best practices for database migration, monitoring tools for Microsoft Fabric, challenges of introducing DevOps in legacy systems, productivity solutions using AI, and updates on Azure SQL Managed Instance features.
Read Full Article
6 Likes
Dbi-Services
391

Image Credit: Dbi-Services
SQLDay 2025 – Wrocław – Workshops
- SQLDay 2025 in Wrocław featured pre-conference workshops on various Microsoft Data Platform topics.
- Workshop sessions included topics such as Advanced DAX, Execution Plans in Depth, Becoming an Azure SQL DBA, Enterprise Databots, Analytics Engineering with dbt, and more.
- Sessions catered to different professionals, ranging from experienced Power BI users to SQL Server professionals and those transitioning to cloud environments.
- SQLDay workshops offered valuable insights into Azure, Power BI, SQL Server, and data engineering, providing attendees with practical knowledge and hands-on experiences.
Read Full Article
23 Likes
For uninterrupted reading, download the app