A naukri.com initiative
Databases
Soais
4

UiPath Agent Builder: A Simple Overview
- UiPath Agent Builder is a tool for creating AI agents—virtual assistants that can understand natural language and interact with UiPath workflows.
- Agent Builder introduces flexible, decision-making logic using AI while being grounded in data and controlled by guardrails.
- It is native to UiPath, low code, and offers governance features like escalation and audit logs for compliance and predictability.
- UiPath is evolving the platform with upcoming support for more AI models, additional templates, and better Langchain support.
Read Full Article
Like
Dev
188

Image Credit: Dev
Introduction to PostgreSQL
- PostgreSQL is an advanced open-source RDBMS supporting SQL and JSON querying, with origins dating back to 1986 at UC Berkeley.
- Key features include ACID compliance, MVCC, and extensibility, making it suitable for various workloads.
- Installation requirements for PostgreSQL include modest hardware specifications and platform-specific installation methods.
- Configuration involves editing files like postgresql.conf and using the psql command-line tool for database management and administration.
- PostgreSQL's architecture follows a client-server model, with key processes like WAL writer and background writer for data management.
- Core concepts cover databases, schemas, tables, data types, constraints, indexes, and views within PostgreSQL.
- SQL operations like CRUD, joins, subqueries, aggregations, and transactions are fundamental to working with PostgreSQL.
- Advanced features include window functions, CTEs, JSONB support, full-text search, and query optimization techniques.
- Security measures like roles, permissions, SSL encryption, and row-level security enhance data protection in PostgreSQL.
- Deployment best practices, scaling strategies, maintenance procedures, and the PostgreSQL ecosystem are crucial for production use.
Read Full Article
11 Likes
Dbi-Services
271
Optimize materialization of Exadata PDB sparse clones
- A company using Exadata sparse clones for database provisioning faced slow materialization times for sparse clones compared to full clones.
- The issue was identified as a result of Oracle sequentially performing online database move operations, slowing down the process.
- Monitoring the materialization process was possible through queries on GV$SESSION_LONGOPS.
- The company optimized the process using Python scripts with cx_Oracle driver, enabling parallel task execution and reducing the materialization time to that of creating a full PDB clone.
Read Full Article
16 Likes
Javacodegeeks
66
Image Credit: Javacodegeeks
Introduction to Apache Kylin
- Apache Kylin is an open-source distributed analytics engine that offers fast OLAP queries on large-scale datasets stored in systems like Apache Hive or HDFS.
- Key features of Apache Kylin include pre-computed cubes, standard SQL support, massive scalability, multi-engine compatibility, security integration, and RESTful APIs.
- Apache Kylin precomputes OLAP cubes offline, stores them for fast retrieval, and integrates with BI tools like Tableau and Power BI.
- Its architecture includes components like Web UI, Metadata Store, Query Engine, Cube Engine, Storage Layer, and REST Server.
- Installation using Docker simplifies local setup, enabling users to quickly create projects, data models, and OLAP cubes in the Kylin Web UI.
- Querying Apache Kylin can be done through its Web UI, BI tools via drivers, or REST API for data automation, facilitating fast analytical insights.
- Apache Kylin is suitable for enterprise BI dashboards, marketing analytics, sales reporting, customer behavior analysis, and telecom data analysis.
- By precomputing cubes, Kylin boosts query speed, making it ideal for interactive dashboards and real-time analytics on big data platforms.
- With its fast analytics capabilities, Apache Kylin serves as a valuable tool for businesses looking to bridge the gap between massive datasets and BI needs.
- Overall, Apache Kylin offers a compelling option for enhancing analytical workloads and enabling real-time business intelligence on big data architectures.
Read Full Article
4 Likes
Discover more
- Programming News
- Software News
- Web Design
- Devops News
- Open Source News
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Javacodegeeks
259
Image Credit: Javacodegeeks
Fix Cannot Load Driver Class: com.mysql.jdbc.driver in Spring Boot
- The 'Cannot Load Driver Class: com.mysql.jdbc.driver' issue in Spring Boot arises when the application can't load the old MySQL driver class due to a mismatch in driver configuration.
- In older Spring Boot 1.x versions, the driver class name is explicitly set in the configuration, while in Spring Boot 2+, it can be auto-detected based on the JDBC URL.
- If the Spring Boot application is upgraded to a higher version with a mismatched driver class configuration, it can lead to the 'Cannot Load Driver Class' exception.
- To resolve this, ensure compatibility between MySQL Connector/J version and the driver class configuration in Spring Boot application properties.
Read Full Article
15 Likes
Dbi-Services
12
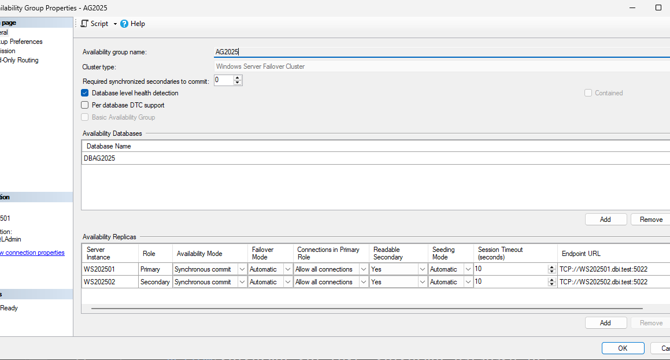
Image Credit: Dbi-Services
SQL Server 2025 – AG Commit Time
- SQL Server 2025 preview has been publicly available for a week now.
- One highlighted Engine High Availability (HA) feature in the blog is Availability Group Commit Time.
- SQL Server 2025 introduces configurable AG Commit Time for better performance in specific scenarios.
- Instructions on how to change the default AG commit time value and measure its impact are provided.
Read Full Article
Like
Silicon
251

Image Credit: Silicon
Oracle ‘To Spend $40bn’ On Nvidia Chips For Stargate Campus
- Oracle plans to spend $40 billion on Nvidia GB200 AI accelerators for a data centre in Texas for the Stargate infrastructure project with OpenAI and SoftBank.
- About 400,000 high-end chips will be purchased by Oracle for training AI systems, with the capacity leased to OpenAI.
- The Abilene, Texas site is the first Stargate project and is expected to provide 1.2 gigawatts of computing power upon completion next year.
- Stargate aims to reduce OpenAI's dependence on Microsoft for computing infrastructure, with investments from various companies totaling billions.
Read Full Article
13 Likes
Medium
280

Image Credit: Medium
The engineering Oracle prompt: Tap into 30 years of dev wisdom in one chat
- The Engineering Oracle is a prompt designed to simulate a seasoned software engineer with 30 years of experience.
- It emphasizes deep consultation over quick fixes, helping with complex architectural problems, debugging, and decision-making.
- The Oracle focuses on context, logical thinking models, and customized solutions rather than hand-wavy responses.
- It begins by asking insightful questions to understand the problem before offering solutions, mimicking how veteran engineers approach problems.
- The Oracle not only looks at code issues but also considers business goals, user needs, and team dynamics.
- It provides tailored solutions based on the specific problem, team dynamics, and technology stack, promoting clarity over mere code snippets.
- This prompt is valuable for tackling complex problems, decision-making scenarios, and team-related dilemmas, offering practical advice grounded in experience.
- The Oracle aims to guide through consequences, not just steps, avoiding the trial-and-error approach that may break systems.
- It's not a replacement for developers but rather an AI that thinks like an experienced developer, offering strategic insights and considerations.
- The Oracle excels in guiding through real-world engineering challenges beyond mere technicalities, considering factors like risks, team dynamics, and long-term implications.
Read Full Article
16 Likes
Dev
2.9k

Image Credit: Dev
Converting JSON Data to Tabular in Snowflake — From SQL to SPL #32
- The task involves extracting information from a multi-layered JSON string in a Snowflake database.
- SpecificTrap field is identified as the grouping field, and details like oid and value are extracted from the first layer array variables.
- In SQL, due to its limitation with multi-layer data, indirect implementations through nested queries and grouping aggregation are required.
- On the other hand, SPL (Structured Programming Language) directly supports multi-layer data access and allows object-oriented access to such structures.
Read Full Article
8 Likes
Dev
349

Image Credit: Dev
My Journey with ASP.NET Core & SQL Server: Lessons Learned
- Yasser Alsousi, a .NET developer, shared lessons learned from his journey with ASP.NET Core and SQL Server.
- Key reasons for choosing ASP.NET Core: cross-platform capabilities, high performance, strong ecosystem, and enterprise-ready features.
- Top 3 beginner tips include mastering C# fundamentals, embracing dependency injection, and following database best practices like starting with SQL Server Express and optimizing with Entity Framework Core.
- Yasser optimized an inventory API from 2s to 200ms response times by adding SQL indexes, implementing caching, and using AsNoTracking() for read-only operations.
Read Full Article
20 Likes
Dev
412
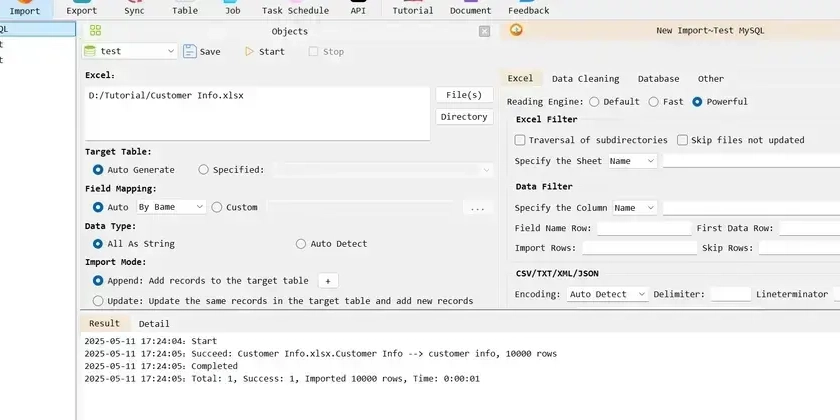
Image Credit: Dev
Fastest way to import excel into mysql
- Introduction to the fastest way to import Excel data into MySQL.
- Preparation involves creating an Excel table for import.
- Steps include creating a new connection, initiating the import process, and optimizing for faster import speed.
- DiLu Converter is highlighted as a powerful tool supporting multiple databases for simplified Excel import and export.
Read Full Article
24 Likes
Siliconangle
232
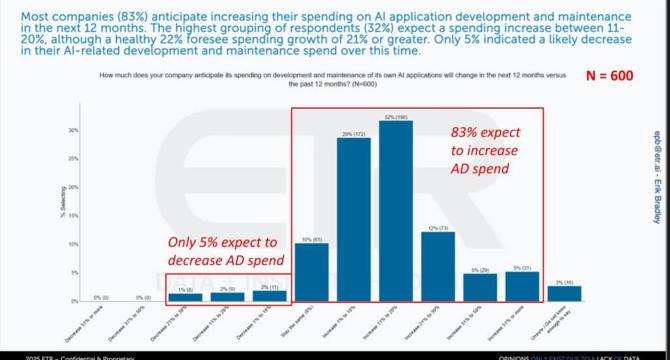
Image Credit: Siliconangle
AI budgets are hot, IT budgets are not
- Many enterprises are still unsure about the benefits of AI investments versus historical IT initiatives like ERP, data warehousing, and cloud computing.
- ETR's data shows a shift towards building in-house AI applications, with 83% of IT decision makers planning to increase spend on AI app/dev in 2025.
- There is a consensus across different buyer types on expanding budgets for custom AI workloads to accelerate time-to-value.
- Enterprises are still in proof-of-concept or early production stages indicating a multi-year investment wave in AI application development.
- Geopolitical tension and shifting policy frameworks are not derailing enterprise AI agendas, with more firms proceeding cautiously than slowing down adoption.
- ROI for AI projects lags with 27% of respondents yet to see tangible returns, indicating enterprises are still in experimentation mode rather than harvesting immediate benefits.
- C-suite executives rank AI initiatives as the second-most vulnerable category to cuts, next to outsourced IT services, highlighting the potential vulnerability of experimental AI funding.
- AI budget growth expectations have retreated, indicating a cautious sentiment towards IT spending due to economic uncertainties and geopolitical unrest.
- Policy uncertainty is causing executives to tap the brakes on net-new IT projects, with 71% acknowledging some form of pullback due to uncertainty.
- Enterprise adoption of specific AI foundation models shows OpenAI's GPT leading in mindshare, with Microsoft's Azure OpenAI Service being widely adopted.
Read Full Article
13 Likes
Dev
25

Image Credit: Dev
🚦 Oracle 19c vs PostgreSQL 15 — The Ultimate Parameter Showdown!
- The article compares Oracle 19c and PostgreSQL 15 across various parameters in a side-by-side checklist.
- Over 200+ parameters in categories like Memory, CPU, I/O, Connections, Optimizer, Logging, Security, Background Jobs, Redo/WAL, and Miscellaneous are compared.
- Parameters like memory allocation, CPU configuration, I/O operations, connection limits, optimizer settings, logging setups, security features, background job controls, and more are included in the comparison.
- It highlights key differences and equivalences between Oracle and PostgreSQL parameters, aiding in tasks like workload migration, database tuning, cloud strategy planning, and parameter mapping.
Read Full Article
1 Like
Pymnts
113

Image Credit: Pymnts
Oracle to Buy $40 Billion Worth of Nvidia Chips for First Stargate Data Center
- Oracle plans to buy $40 billion worth of Nvidia chips to power the first Stargate project, a data center in Abilene, Texas.
- The data center is expected to be operational by mid-2026 and will provide 1.2 gigawatts of power, making it one of the largest in the world.
- Stargate project, announced by President Donald Trump, aims to build AI-focused data centers in the U.S. with the first 10 in Texas.
- AI data centers like Stargate's require specialized hardware and infrastructure to handle the computational power needed for AI workloads.
Read Full Article
6 Likes
Amazon
38

Image Credit: Amazon
Explore the new openCypher custom functions and subquery support in Amazon Neptune
- Amazon Neptune has released openCypher features as part of the 1.4.2.0 engine update, offering support for custom functions and CALL subqueries.
- Neptune is a managed graph database service providing open graph query languages like openCypher, Apache TinkerPop Gremlin, and SPARQL 1.1.
- The latest engine release introduced features including CALL subqueries for running specific queries on a node-by-node basis.
- The CALL function enables executing additional MATCH statements against a collection of data in openCypher queries.
- Neptune's openCypher custom functions include textIndexOf, collToSet, collSubtract, collIntersection, collSort, collSortMaps, collSortMulti, and collSortNodes.
- These functions support tasks like searching text, creating unique sets, and sorting collections of data in various ways.
- Examples provided showcase how these custom functions can be utilized for advanced querying and data manipulation in Neptune.
- Users can now leverage these new features to enhance their graph applications and perform complex operations efficiently.
- Neptune also offers options for bulk loading data into Neptune Database or Neptune Analytics, providing practical data management solutions.
- The post concludes with suggestions on getting started with Neptune, such as creating clusters, upgrading to the latest version, and using open source tools like graph-explorer.
Read Full Article
2 Likes
For uninterrupted reading, download the app