A naukri.com initiative
Programming News
Dev
258

Image Credit: Dev
The Rust Renaissance: Why OpenAI and the Tech World Are Shifting from Node.js for High-Performance Tools
- OpenAI's shift to Rust for rewriting its AI programming tools signifies a move towards high-performance toolchains and improved developer experience.
- The transition of the Codex CLI from Node.js to Rust highlighted the industry's trend towards embracing Rust for future tools.
- Rust provides a lightweight, self-contained binary executable, eliminating the need for runtime or dependency libraries, offering a clean user experience.
- Rust enhances security for AI tools like Codex CLI through better sandboxing mechanisms and native bindings for system-level security features.
- Rust's unique memory management system without garbage collection ensures predictable performance, making it ideal for continuous and demanding applications like AI tools.
- OpenAI benefits from Rust's extensive low-level libraries when implementing complex native protocols, enabling faster development and higher code quality.
- The industry trend towards 'Rustification' is evident, with projects like Rolldown aiming to leverage Rust's performance benefits over existing solutions.
- ServBay, embracing Rust support, aims to simplify development environments by handling dependency management and providing a unified platform for various technologies.
- ServBay allows developers to manage Rust applications, Node.js/PHP projects, and databases in a single interface, promoting efficiency and ease of use.
- As the tech industry moves towards high-performance tools, embracing change and choosing efficient tools like Rust becomes crucial for developers seeking productivity.
Read Full Article
15 Likes
Dev
419

Image Credit: Dev
Charts in CSS
- CSS offers new and evolving techniques for creating charts, such as using a
element for accessibility and simplicity.
- Attributes like data-value can be utilized with typed attr() in CSS to enhance chart functionality.
- Custom elements like
with attributes for min, max, and role can be used for building responsive charts. - Calculation of heights and coordinates in CSS enables the creation of column, area, line, bar, pie, and donut charts.
- Grid lines and numeric labels can be added to enhance the visual representation of charts.
- Variants like area, line, bar, pie, donut charts can be created using similar markup with additional attributes.
- Responsive charts can be achieved by setting column counts per breakpoint and using @container queries for styling adjustments.
- Demo examples illustrate the implementation of various types of charts and how they can adapt responsively.
- Safari and Firefox may require a JavaScript fallback for certain features like typed attr() to ensure full functionality.
- Overall, CSS advancement allows for more flexibility and creativity in designing charts directly in stylesheets.
Read Full Article

25 Likes

Speckyboy
4w
325


Image Credit: Speckyboy
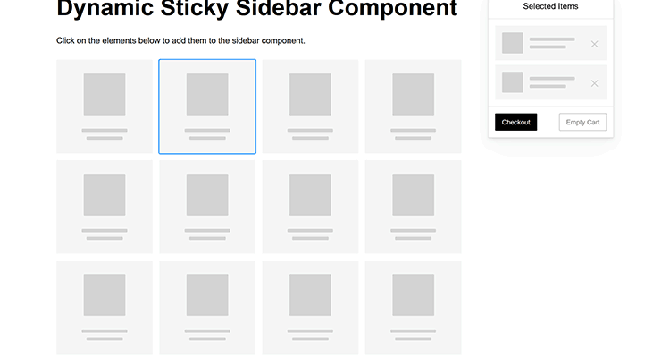
8 CSS & JavaScript Snippets for Creating Sticky Elements
- Sticky design elements like headers and sidebars help users navigate long pages and maintain visibility of important features while scrolling.
- CSS provides a simple way to create sticky elements using the position property, while JavaScript can be used for more complex functionality.
- Various creative CSS and JavaScript snippets for implementing sticky elements were showcased on CodePen to enhance user experience.
- Examples included a pure CSS header animation, a responsive sidebar navigation, a sticky table header and column, and sticky sections for long scrolls.
- Other snippets featured multi-navigation sticky bars, a sticky video implementation, and a dynamic sticky sidebar component for shopping carts.
- These snippets demonstrate how sticky elements can be used beyond traditional navigation, offering creative and interactive ways to engage users.
Read Full Article
19 Likes
Logrocket
4w819
Image Credit: Logrocket
Leader Spotlight: Taking lessons from big tech to healthcare, with Sriharsh Boddapati
- Sriharsh Boddapati, Senior Director at CareSource, discusses applying lessons from big tech to healthcare and vice versa, emphasizing the importance of patient experience in the healthcare industry.
- He addresses misconceptions about building digital products in healthcare, highlighting the shift towards value-based care models prioritizing patient outcomes.
- Sriharsh views regulatory compliance as providing valuable insights early on in product development, guiding teams to align with industry needs.
- He explores the untapped opportunities for human-centered design in healthcare, focusing on understanding patient care settings and compliance requirements.
- Bringing principles from big tech, Sriharsh stresses the importance of agility and rapid iteration in healthcare product development to address the industry's fragmentation.
- He discusses how healthcare's long-term focus on sustainability and compliance can provide valuable lessons for big tech firms entering new markets, emphasizing user needs and regulatory nuances.
- Sriharsh emphasizes the value of building trust and safety into products early on, particularly when incorporating AI and ML models, to ensure long-term user retention.
- In summary, Sriharsh advocates for embracing agility in responding to user needs and regulations, which he believes healthcare excels at and could serve as a lesson for big tech companies entering regulated markets.
- His biggest takeaway is that while industries may differ in settings, the fundamentals of designing good products remain consistent, emphasizing the importance of adapting practices to match specific industry demands.
Read Full Article
19 Likes
Discover more
- Software News
- Web Design
- Devops News
- Open Source News
- Databases
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Medium
4w62
Image Credit: Medium
A Simple and Profound Bond: The Life and Ancient Custom of an Unknown Man in Central Zagros…
- The people of Zagros have ancient customs and beliefs, valuing every aspect of nature and considering everything in the world as alive.
- An unknown man in Zagros displayed a profound respect for nature, never wasting water and showing reverence for all living beings around him.
- The man's actions are rooted in ancient traditions that teach living in harmony with nature and respecting the sanctity of water and earth.
- His teachings remind us to protect life-springs, live in harmony with the cosmos, and treat the earth not as a possession but as kin.
Read Full Article
3 Likes
Javacodegeeks
4w383
Image Credit: Javacodegeeks
Read Defined Variable In Gradle
- Gradle is a powerful build automation tool that allows defining build-time variables in the build.gradle file and accessing them in Java code.
- One approach involves generating a Java class during the build process containing static constants initialized with Gradle-defined values, making them available at compile-time.
- Another approach is to write Gradle variables into a properties file that can be read by an application at runtime, ideal for apps requiring configurable environments.
- For dynamic environment configurations, variables can be injected as system properties during application launch, providing runtime availability without additional files or generated code.
Read Full Article
23 Likes
Medium
4w393
Image Credit: Medium
Why Remote Work Is Secretly Destroying Junior Developers’ Careers
- Remote work is posing challenges for junior developers, hindering their career growth.
- Lack of immediate support and guidance in remote work settings lead to confidence erosion among junior developers.
- An analysis of junior developers' experiences during the pandemic reveals alarming trends of stunted career progression.
- The story of Sarah, a coding bootcamp graduate facing hurdles in remote work, exemplifies the struggles of junior developers in the current scenario.
Read Full Article
23 Likes
Dev
4w236
Image Credit: Dev
Docker Multi-Stage Builds: Your Secret Weapon for Lean, Mean Container Machines
- Before multi-stage builds, Docker images were bloated with unnecessary tools and dependencies, leading to large image sizes.
- Multi-stage builds in Docker allow for selective copying of artifacts from one stage to another, resulting in leaner images.
- Examples include transforming a bloated React app Dockerfile into a lean, multi-stage masterpiece, reducing image size significantly.
- Go applications and Python Flask applications also benefit from multi-stage builds, resulting in smaller images.
- Advanced patterns like the Testing Stage Pattern and Development vs Production Pattern optimize the use of multi-stage builds for different purposes.
- Best practices for multi-stage builds include ordering layers efficiently, using specific base images, and cleaning up in the same layer.
- Common pitfalls to avoid in multi-stage builds include copying unnecessary files between stages, not using build arguments effectively, and ignoring security considerations.
- Multi-stage builds offer faster deployments, lower costs, better security, and cleaner architecture, enhancing the Docker experience and optimizing runtime environments.
- Switching to multi-stage builds can significantly improve Docker image efficiency and benefit deployment pipelines in terms of speed and cost.
- Remember, less is more in the world of containers, and multi-stage builds help achieve a streamlined production environment.
Read Full Article
14 Likes
Dev
4w370
Image Credit: Dev
Understanding Local and Remote Model Context Protocols
- The Model Context Protocol (MCP) aims to standardize how AI models access data and tools, likened to a 'USB-C for AI.'
- Local MCP Servers run on the same machine as the client and communicate via stdio, ideal for local integrations.
- Local MCP Servers require manual setup and direct management of secrets, offering speed and control over data processing.
- Remote MCP Servers, hosted in the cloud, use HTTP and SSE for communication, providing easy access from anywhere.
- Remote MCP Servers offer simple setup, always up-to-date features, and scalability, but require an internet connection.
- Choosing between a Local and Remote MCP Server depends on factors like deployment needs, data sensitivity, and user accessibility.
- Local servers are preferred for developers testing integrations and handling sensitive data locally, while remote servers are suitable for web-based AI agents and broad access.
- Ultimately, the decision between local and remote MCP servers should be based on understanding the trade-offs and selecting the right tool for the specific use case.
- Local MCP servers offer control and speed, while remote servers provide accessibility and ease of use for multiple users.
- Consider factors like security requirements and user base when choosing between local and remote MCP servers.
- The choice depends on individual use cases, with local servers focusing on control and speed, and remote servers on accessibility and ease of use for broader users.
Read Full Article
22 Likes
Dev
4w902
Image Credit: Dev
7 Strategies to Stay Sane in the Never-Ending Tech Hype Cycle
- Developers are overwhelmed by the constant tech hype and new AI tools promising to revolutionize the industry.
- To stay sane, it is suggested to choose the battles worth fighting and focus on what matters for individual growth.
- Taking an information diet, preferring long-form content, and investing in proven technologies are recommended strategies.
- Embracing just-in-time learning and understanding that new hypes will always emerge are key to navigating the tech industry.
Read Full Article
24 Likes
Medium
4w3.6k
Image Credit: Medium
Google Pushes the Limits of AI Coding with Enhanced Gemini 2.5 Pro Model
- Google introduced Gemini 2.5 Pro as part of its generative AI toolkit and is now enhancing its capabilities based on real-world usage.
- The update reflects Google's strategy to attract developers and business users, aiming to dominate the B2B landscape with its AI offerings.
- Gemini 2.5 Pro now serves as a digital co-pilot for developers, allowing for faster development cycles and lower costs for businesses.
- Google is gathering insights to tailor future features, potentially introducing subscription models or enterprise licensing around the product.
Read Full Article
22 Likes
Pymnts
4w334
Image Credit: Pymnts
Core System Upgrades Move Insurers Toward Real-Time Payments
- Insurance firms are facing a decision on whether to build, buy, or partner for tech expertise in digitalizing operations for payment processing.
- Partnerships can help insurers improve customer experience and modernize fund flows, leading to faster claims processing and cost reduction.
- Offering a variety of payment methods such as push to debit, PayPal, Venmo, and real-time options is crucial for individual policyholders.
- One Inc, specializing in premium collection and claims payments, emphasizes integration with carriers' core systems for operational efficiency, reducing time and costs.
Read Full Article
20 Likes
Dev
4w338
Image Credit: Dev
Implementing the Outbox Pattern with PostgreSQL in Brighter
- This article introduces the implementation of the outbox pattern with PostgreSQL in Brighter to ensure transactional consistency between database updates and message publishing using .NET 8, Brighter, and PostgreSQL.
- The project involves sending commands to create orders and sending messages (OrderPlaced & OrderPaid) based on the outcome, while ensuring no messages are sent in case of failures.
- Requirements include .NET 8+, Podman (or Docker) for running local containers with PostgreSQL and RabbitMQ, and specific NuGet packages for Brighter and RabbitMQ integration.
- The implementation involves message creation, mappers for events, request handlers for logging messages, the creation of new orders with handling of success and failure scenarios, and configuring PostgreSQL for the outbox pattern with limitations and future improvements mentioned.
Read Full Article
20 Likes
Dev
4w66
Image Credit: Dev
Quark’s Outlines: Python Object Identity
- Every object in Python has a unique identity that remains fixed as long as the object exists.
- Object identity can be checked using the id() function and compared using the is operator.
- Object value and identity are distinct concepts in Python, used for different purposes.
- Object identity helps in tracking memory and object behavior in Python.
- Python introduced object identity concepts early on to manage memory efficiently.
- Object identity plays a crucial role in tracking names and objects in Python.
- Using is operator helps in checking if two names point to the same object in memory.
- Python handles shared mutation and immutable types using object identity principles.
- By copying or slicing objects, Python allows avoiding accidental shared state.
- Object identity in Python contributes to efficient memory management and understanding object relationships.
Read Full Article
4 Likes
PlanetPython
4w142
Image Credit: PlanetPython
Python Bytes: #435 Stop with .folders in my ~/
- The Python Bytes episode #435 covered several topics including platformdirs, poethepoet, Python Pandas adopting PyArrow, and pointblank for data validation.
- Platformdirs is a Python module that determines platform-specific directories more effectively than appdirs, providing better typing, directory support, cleaner internals, and community stewardship.
- Poethepoet is a task runner that facilitates easy task definition, particularly working well with poetry or uv.
- Python Pandas is switching from NumPy to PyArrow in its upcoming release, version 3.0, to enhance performance significantly with faster loading and reading of columnar data.
- Pointblank was highlighted as a tool that offers a chainable API for powerful and aesthetically pleasing data validation.
Read Full Article
8 Likes
For uninterrupted reading, download the app