A naukri.com initiative
Software News
Medium
206
Image Credit: Medium
You don’t have to be a genius to write great code
- The article emphasizes eight principles to design and write better code based on experience and lessons learned.
- Promoting clear, boring code over clever, tricky code is highlighted to benefit future developers.
- It stresses the importance of readability and predictability in code for easier understanding.
- The advice is to avoid over-abstracting early on as it can lead to unnecessary complexity and confusion.
- Anticipating change and building flexible code rather than striving for perfection is recommended.
- Creating clear boundaries in code through modules, services, and functions is essential for scalability.
- Designing for operability and making systems easy to monitor and recover from failures is crucial.
- Consistency, following team conventions, and designing with the whole system in mind are highlighted for reliability.
- Encouraging systems thinking to consider the broader implications of code interactions for better design decisions.
- The article suggests gradually incorporating these principles, focusing on a few at a time for better code quality.
Read Full Article
12 Likes
Towards Data Science
112

From a Point to L∞
- The article discusses the differences between L₁ and L₂ norms and their significance in shaping models and measuring error in AI.
- It explores when to use L₁ versus L₂ loss and how they affect model regularization and feature selection.
- The concept of mathematical abstraction is highlighted as a key aspect in understanding norms like L∞.
- L₁ and L₂ norms play different roles in optimization and regularization, affecting the behavior of models.
- The article delves into L₁ and L₂ regularization methods like Lasso and Ridge regression, explaining their impact on model sparsity and generalization.
- It shows how the choice between L₁ and L₂ loss can influence outcomes in Generative Adversarial Networks (GANs) in terms of image output.
- The generalization of distance to Lᵖ space is discussed, leading to the introduction of the L∞ norm.
- The L∞ norm, also known as the max norm, is characterized by its limit and utility in providing a uniform guarantee.
- Various real-world applications of the L∞ norm are highlighted, showcasing its importance in different contexts.
- The article concludes by emphasizing the importance of understanding distance measures and their implications in modeling decisions.
Read Full Article
6 Likes
Tech Radar
359
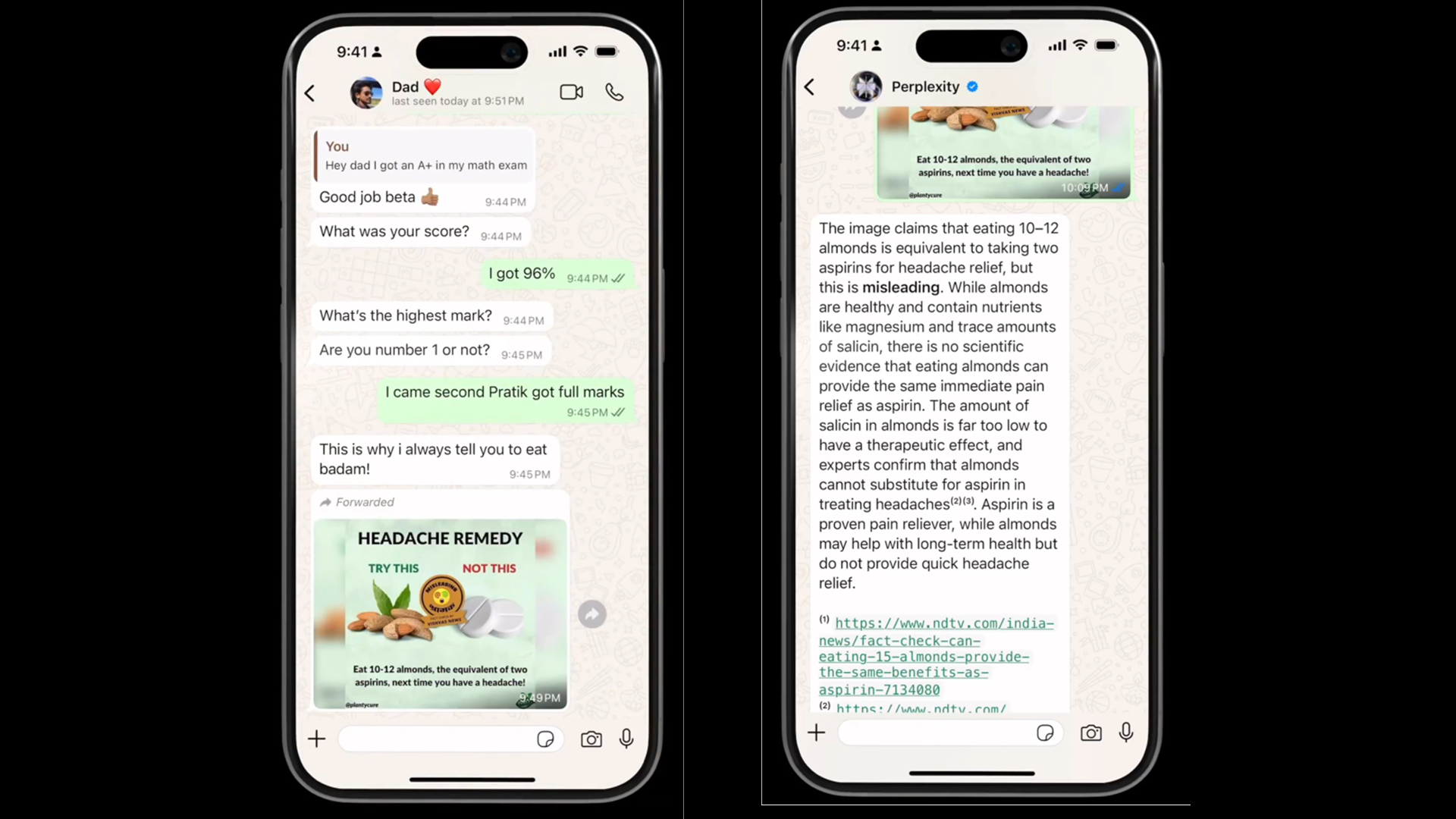
Image Credit: Tech Radar
You can now fact check anybody’s post in WhatsApp – here’s how
- Perplexity AI's new WhatsApp integration allows instant fact-checking within the app.
- Users can forward any questionable message to Perplexity's WhatsApp number to receive fast, sourced explanations in over 20 languages.
- The feature aims to help users navigate and verify information shared in private group chats to combat misleading posts.
- Perplexity's real-time fact-checking feature provides links to sources and helps users verify the accuracy of information circulated in group chats.
Read Full Article
21 Likes
Towards Data Science
151
Build and Query Knowledge Graphs with LLMs
- A Knowledge Graph is a structured representation of information connecting concepts, entities, and relationships, enhancing the performance of Large Language Models (LLMs) in Retrieval Augmented Generation applications.
- GraphRAG employs a graph-based representation of knowledge to improve information serving to LLMs compared to standard approaches.
- Challenges in traditional applications include limitations in reasoning at an inter-document level and reliance on vector similarity for retrieval.
- Organizing knowledge bases into graph structures with entities, relationships, and attributes allows for more contextual and implicit references.
- The article details the transformation from vector representations to Knowledge Graphs and extracting key information for building them.
- The technology stack breakdown includes tools like Neo4j for graph databases, LangChain for LLM workflows, and Streamlit for frontend UI.
- Docker is used for containerization, enabling local development and deployment of the project.
- From text corpus to Knowledge Graph involves steps such as loading files, cleaning and chunking content, extracting concepts, embedding chunks, and storing in the graph.
- Graph-informed Retrieval Augmented Generation strategies include Enhanced RAG, Community Reports, Cypher Queries, Community Subgraph, and Cypher + RAG.
- Strategies are compared based on factors like tokens usage, latency, and performance to optimize for accuracy, cost, speed, and scalability.
Read Full Article
8 Likes
Discover more
- Programming News
- Web Design
- Devops News
- Open Source News
- Databases
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Hackernoon
292

Image Credit: Hackernoon
Bybit Showcased Innovative Payments And Crypto Solutions At Web Summit Rio 2025
- Bybit showcased its innovative payments and crypto solutions at Web Summit Rio 2025, presenting future-ready crypto offerings and innovative payments solutions.
- Bybit launched Bybit Pay in Brazil powered by Transfero, offering a blockchain-based payment gateway and seamless crypto-to-fiat experience with features like QR code support and support for multiple currencies.
- Bybit aims to become the lifestyle partner of the crypto community in LATAM and recently announced a strategic partnership with Tomorrowland Brasil, making crypto a key focus at the iconic music festival.
- Bybit, as the exclusive Payment Partner for Tomorrowland, is bridging the gap between music and the crypto-savvy generation, aiming to make crypto transactions easy and borderless for everyday users.
Read Full Article
17 Likes
Medium
426

Image Credit: Medium
Why Zig Feels Like Programming in 1995 (And That’s Not a Compliment)
- Zig, a modern systems programming language, is often likened to coding in the mid-90s with its emphasis on control and lack of abstractions.
- While Zig's philosophy of being in control of everything is respectable, it can lead to discomfort with raw pointers, manual memory management, cryptic errors, and poor ergonomics.
- For those nostalgic for programming in C in the mid-90s, Zig may feel familiar, but for those aiming to develop modern, scalable, and user-friendly software, it might seem regressive.
- Zig's insistence on manual control over memory allocation and deallocation, along with the absence of a garbage collector, implicit behavior, and secret memory allocations, places a heavy burden on the programmer.
Read Full Article
25 Likes
Hackernoon
130

Image Credit: Hackernoon
Bitcoin Seoul 2025 To Host Global Industry Leaders For Asia’s Largest Bitcoin-Focused Conference
- Bitcoin Seoul 2025, Asia’s largest Bitcoin-focused conference, is set to take place from June 4 to 6, 2025, in Seoul, South Korea.
- The event will feature industry leaders, executives, and community members discussing Bitcoin's evolution, global trajectory, real-world adoption, and more.
- Special sessions will include insights from executives leading Bitcoin adoption in companies like MetaPlanet and The Blockchain Group, as well as Bitcoin community leaders from various countries.
- The event structure includes VIP, Industry, and Public days focused on different aspects of Bitcoin finance, adoption stories, and community engagement.
Read Full Article
7 Likes
Medium
143

Image Credit: Medium
Why Your CI/CD Pipeline Is a House of Cards: 8 Critical Failures Waiting to Happen
- CI/CD pipelines can collapse when unexpected conditions occur, causing catastrophic failures.
- Vulnerabilities like false test confidence, hardcoded credentials, unpinned dependencies, and lack of access controls can lead to disasters.
- Problems such as failing to reproduce bugs due to short artifact retention policies and normalizing test failures can weaken pipelines.
- Automated deployments without considering business context can pose risks, and untested rollback processes can fail in crucial situations.
- To build a resilient pipeline, focus on observability, plan for failure, and evolve through stages of CI/CD maturity.
- Stages of CI/CD maturity include repeatable, managed, and resilient, achieved through continuous investment and cultural shifts.
- Successful organizations treat their CI/CD pipelines as products, with dedicated ownership and ongoing improvements.
- Addressing vulnerabilities proactively can transform a fragile pipeline into a strong foundation for development processes.
- CI/CD failures often stem from common weaknesses like non-reflected real-world testing and unmonitored test failures.
- Being aware of these vulnerabilities and implementing safeguards can prevent disasters in CI/CD pipelines.
Read Full Article
8 Likes
Towards Data Science
365
Attaining LLM Certainty with AI Decision Circuits
- AI agents have revolutionized automation by handling complex tasks quickly and efficiently, but human review can become a bottleneck in decision-making processes.
- LLM-as-a-Judge technique involves using one LLM process to judge the output of another, creating a confusion matrix that includes true-positives and false-negatives.
- AI Decision Circuits mimic error correction concepts from electronics by utilizing redundant processing, consensus mechanisms, validator agents, and human-in-the-loop integration.
- These circuits ensure robust decision-making by employing multiple agents, voting systems, error detection methods, and human oversight.
- The reliability of AI Decision Circuits can be quantified using probability theory to determine failure probabilities and expected errors.
- By combining different validation methods and logic in decision-making, the system can enhance accuracy and confidence levels in responses.
- Enhanced filtering for high confidence results and additional validation techniques can further improve the system's accuracy and reduce errors.
- A cost function can help tune the system by balancing parser costs, human intervention costs, and undetected error costs to optimize performance.
- The future of AI reliability lies in developing systems that combine multiple perspectives, strategic human oversight, and high precision to ensure consistent and trustworthy performance.
- These circuit-inspired approaches aim to create AI systems with near-perfect accuracy and guarantee reliability, setting a standard for mission-critical applications in the future.
Read Full Article
21 Likes
Towards Data Science
348
Why I stopped Using Cursor and Reverted to VSCode
- In the article, the author shares their journey of switching from VSCode to Cursor as a Data Scientist.
- The author initially praised Cursor for its interface similarity to VSCode and features like multiple LLMs and the 'Composer' project code generation.
- However, the author eventually reverted back to VSCode primarily due to GitHub Copilot's enhanced AI capabilities, including implementing state-of-the-art LLMs.
- VSCode's support for Jupyter Notebooks, GitHub Copilot instructions, and easier AI-assistance integration played a significant role in the author's decision.
- Cost-wise, the author found VSCode and GitHub Copilot more valuable than Cursor, especially considering professional usage and alignment.
- Microsoft's focus on enhancing GitHub Copilot features at a rapid pace placed it ahead of competitors like Cursor in the AI coding assistant space.
- The author encourages users to choose their IDE based on personal experience rather than online buzz, highlighting the continuous innovation in the coding assistant market.
- Personal opinions shared in the article are based on the author's experience, and they have no affiliations with Cursor, VSCode, or GitHub Copilot.
- In conclusion, the author expresses satisfaction with using VSCode and believes Microsoft's progress with GitHub Copilot positions it well in the AI-assistant IDE market.
- The author emphasizes that feature adoption across IDEs should not trigger constant switching, urging users to make informed decisions for their coding workflows.
Read Full Article
20 Likes
Towards Data Science
372
The Difference between Duplicate and Reference in Power Query
- Power Query offers Duplicate and Reference features for loading data twice with distinctions in functionality.
- Duplicate copies M-Code to create a new table, while Reference creates a new table based on an existing one.
- SQL Profiler and Power Query Diagnostics are tools used to analyze the behavior of these features.
- When creating a Duplicate, the data is retrieved twice with separate connections, as shown in SQL Profiler.
- Creating a Reference also results in the data being read twice, indicating no difference in load traffic compared to Duplicate.
- The key difference is that Duplicate creates an independent new table, whereas Reference is based on the outcome of the referenced table.
- Reference is suitable for extracting subsets without affecting the original table, while Duplicate is needed for operations like merging tables due to circular references.
- Consider potential conflicts during data loading, especially from sources like Excel, where adjusting settings for parallel loading may be necessary.
- In conclusion, there is no difference in load performance between Duplicate and Reference in Power Query as both load data independently.
- Understanding the distinctions between these features is vital for efficient data loading and transformation processes in Power Query.
Read Full Article
22 Likes
Engadget
202

Image Credit: Engadget
NotebookLM, the acceptable face of Google AI, is getting an app in May
- NotebookLM, the Google research tool known for AI-generated podcasts, will launch an official app on May 20, 2025, coinciding with Google I/O.
- Users can pre-register for the Android or iOS version, retaining core functionality for uploading various sources like PDFs, URLs, YouTube videos, and text.
- NotebookLM evolved from Project Tailwind in I/O 2023 and now offers services in over 50 languages, making it a trustworthy AI tool grounded in chosen documents.
- As part of Google's Gemini product focus at I/O 2025, NotebookLM's app release signifies its permanence, hinting at potential AI product reveals on May 20.
Read Full Article
12 Likes
Medium
35

Image Credit: Medium
Functional Programming Tricks That Work Well in JavaScript
- Functional programming in JavaScript heavily relies on closures and memory management behind the scenes, especially in methods like map, filter, and reduce.
- Functions passed into map, filter, or reduce carry a 'memory' (closure) of the variables from the environment in which they were created.
- Map creates a new array by applying a function to each item, maintaining access to variables via closures.
- Filter tests and decides whether to keep items based on a function's result, benefitting from closure to hold onto external variables.
- Reduce accumulates a single result by passing an accumulator through each step with closure maintaining outside values.
- JavaScript's reference-based memory model for arrays and objects encourages immutability to avoid unexpected side effects.
- Immutability involves creating new objects based on the original, preventing shared memory changes and enhancing data predictability.
- Immutable patterns allow for safer data manipulation by controlling shared memory creation.
- Functional programming concepts naturally align with closures, references, and immutability in JavaScript for cleaner and more predictable code.
- By understanding these concepts, using map, filter, reduce, and immutable patterns becomes a natural and effective way of working in JavaScript.
Read Full Article
2 Likes
Medium
8

Image Credit: Medium
Why Thread Priorities in Java Do Not Guarantee Execution Order
- Java thread priorities are treated as a suggestion rather than a strict rule by the operating system.
- Each thread in Java has a priority value between 1 and 10.
- Setting a thread's priority does not directly control when it will run or enforce a strict execution order.
- The JVM communicates the thread's priority to the operating system, which ultimately decides how to prioritize threads.
- Different operating systems handle thread priorities differently, not always aligning with Java's priority scale.
- Operating systems like Windows translate Java priorities into their own thread-priority constants, impacting thread scheduling.
- Threads can voluntarily yield the CPU through methods like Thread.sleep() or Thread.yield(), affecting their execution order.
- Thread behavior can appear unpredictable due to preemptive multitasking and various factors influencing thread scheduling decisions.
- Relying solely on thread priorities for precise program behavior is risky, and using synchronization mechanisms is more reliable.
- Concurrency design around synchronization tools rather than thread priorities can lead to more predictable program execution.
Read Full Article
Like
Infoq
13

Image Credit: Infoq
QCon London 2025 Day 3: AMQP Politics, Serverless Databases, Betrayal in Security and Architecture
- Day three of the 19th annual QCon London conference focused on AMQP Politics, Serverless Databases, and Security in Architecture.
- John O'Hara's keynote on AMQP traced the evolution of the protocol, emphasizing the importance of dedicated leadership and thorough specifications.
- AMQP, created in 2003, is ISO-certified, processing 10 trillion messages per day with implementations like RabbitMQ and Apache Qpid.
- Alex Seaton presented on building a database without a server, highlighting the complexities of object storage and Conflict-Free Replicated Data Types (CRDTs).
- Seaton discussed challenges like clock drift, distributed locking, and the subtleties of CRDTs in database management.
- Shana Dacres-Lawrence's presentation emphasized the relationship between security and architecture, warning against betraying one at the cost of both.
- Dacres-Lawrence outlined defense strategies against betrayal, advocating for open communication, technology tools, automation, validation, and collaborative culture.
- Key takeaways included the significance of consistency, adopting a 'shift-left' approach, being intentional, and ensuring that security guides architecture while architecture shapes security.
- The QCon London conference delved into the complexities of AMQP, serverless databases, and the critical intersection between security and architecture.
- Speakers highlighted the importance of dedicated leadership, technological advancements, and the interplay between trust, security, and architectural integrity.
Read Full Article
Like
For uninterrupted reading, download the app