A naukri.com initiative
Data Science News
Analyticsindiamag
237

Image Credit: Analyticsindiamag
Why Smallest.ai is Contesting the Idea of ‘LLMs’
- Smallest.ai founder focuses on global markets to scale technology for India's development.
- India's B2B market challenges lead startups to prioritize global monetization for expansion.
- 'Smallest.ai' prioritizes small, specialized AI models for enterprise voice AI technology.
- By offering high-performance text-to-speech models, 'smallest.ai' targets international markets for growth.
- The company sees critical differentiation in training models from scratch for precise control.
Read Full Article
14 Likes
Analyticsindiamag
50

Image Credit: Analyticsindiamag
Fi.Money Launches Protocol to Connect Personal Finance Data with AI Assistants
- Fi.Money has launched the first consumer-facing implementation of a model context protocol (MCP) for personal finance.
- Fi MCP aims to integrate users' financial data seamlessly into AI assistants, allowing for private and intelligent conversations about money.
- Users can consolidate their entire financial life and connect it to AI tools, enabling context-aware responses based on actual financial information.
- Fi Money's MCP feature empowers users to securely connect their financial data with AI assistants for more meaningful interactions about their finances.
Read Full Article
3 Likes
Analyticsindiamag
150

Image Credit: Analyticsindiamag
Meet the Winners of the GCC Excellence Awards
- AIM's MachineCon GCC Summit 2025 celebrated excellence in AI and technology innovation.
- Champions like Air Products, Align Technology, Bristol Myers Squibb, and others were recognized.
- Awards categories included talent development, collaboration models, sustainability, and digital transformation.
- Companies like Pfizer, Lowe’s India, Genpact, and StoneX received accolades for their contributions.
Read Full Article
8 Likes
Analyticsindiamag
283

Image Credit: Analyticsindiamag
‘Agentic AI isn’t Instant Like Popcorn’
- Despite high agentic AI expertise claims, enterprises allocate less budget for it.
- Agentic AI tools first gained traction among individual users before enterprise adoption.
- Deloitte's collaboration with Google Cloud aims to enhance customer and employee experiences.
Read Full Article
16 Likes
Medium
312

Image Credit: Medium
Why AI Will Never Replace Mathematicians (But Math is Secretly Running AI)
- Artificial intelligence relies on thousands of mathematical equations for its operations.
- Mathematics forms the foundation of machine learning, with neural networks executing math operations.
- Probability theory, differential calculus, and geometry are fundamental to AI's functioning.
- Advanced mathematics underpins AI breakthroughs, with tools like Monte Carlo methods and numerical analysis.
- Understanding AI's mathematical foundations is crucial for responsible deployment and innovative solutions.
Read Full Article
18 Likes
Analyticsindiamag
371

Image Credit: Analyticsindiamag
HCLSoftware Launches Domino 14.5 With Focus on Data Privacy and Sovereign AI
- HCLSoftware launched HCL Domino 14.5 focusing on data privacy and sovereign AI for governments and regulated organizations.
- Domino 14.5 introduces Domino IQ, a sovereign AI extension, giving organizations full control over AI models and data to comply with regulations.
- The release aims to reduce reliance on foreign cloud services, helping public sector bodies safeguard sensitive information.
- Key updates in Domino 14.5 include BSI certification, enhanced security tools, and compliance with the European Accessibility Act.
Read Full Article
22 Likes
Analyticsindiamag
398

Image Credit: Analyticsindiamag
Mitsubishi Electric Invests in AI-Assisted PLM Systems Startup ‘Things’
- Mitsubishi Electric Corporation has invested in Things, a startup providing AI-assisted product lifecycle management systems.
- This marks the 12th investment by Mitsubishi Electric's ME Innovation Fund.
- The collaboration aims to address challenges in the manufacturing industry through generative AI technology.
- The partnership intends to enhance competitiveness, improve PLM systems, and accelerate global DX solutions.
Read Full Article
11 Likes
Educba
328
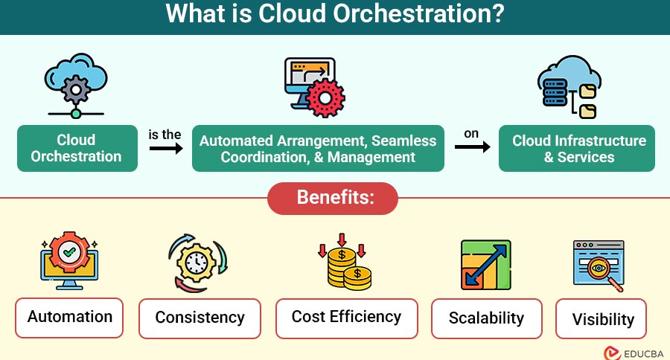
Image Credit: Educba
Cloud Orchestration
- Cloud Orchestration automates cloud infrastructure coordination and management for efficient operations.
- It involves integrating tasks into workflows, ensuring applications and resources function seamlessly.
- Tools like AWS CloudFormation, Azure Resource Manager, and Kubernetes facilitate cloud orchestration.
- Cloud Orchestration streamlines workflows, enhances efficiency, and improves scalability and cost-effectiveness.
Read Full Article
19 Likes
Analyticsindiamag
1.2k

Image Credit: Analyticsindiamag
The Tech Company That is Meesho
- Meesho files DRHP to raise ₹4,250 crore through IPO, targeting Tier 2,3 cities.
- The company values at $4 billion, celebrates profitability milestone, and open-sources ML platform.
- BharatMLStack, OnFS, and Trufflebox UI are core components of Meesho's tech stack.
- Meesho leverages AI for user-centric generative capabilities and customer support initiatives.
- Numerous Indian startups focusing on in-house tech stacks to power platform services.
Read Full Article
20 Likes
Analyticsindiamag
62

Image Credit: Analyticsindiamag
AI to Track Facial Expressions to Detect PTSD Symptoms in Children
- A research team from the University of South Florida (USF) has developed an AI system that can identify post-traumatic stress disorder (PTSD) in children.
- The AI system analyzes subtle facial muscle movements to detect PTSD symptoms in children who may struggle to communicate their distress through traditional methods like interviews and questionnaires.
- The AI system extracts non-identifiable metrics such as eye gaze, mouth curvature, and head position from video footage to respect privacy and ethical boundaries.
- While still in early stages, the AI tool is seen as a clinical augmentation to help therapists pick up on emotional signals that trained professionals might miss in real time, potentially transforming mental health diagnostics for children.
Read Full Article
3 Likes
Analyticsindiamag
380

Image Credit: Analyticsindiamag
Canva Partners With NCERT to Launch AI-Powered Teacher Training
- Canva partners with NCERT to launch free teacher training and certification programs on the DIKSHA platform, aimed at enhancing digital literacy and AI proficiency among educators in India.
- Indian teachers will have access to Canva's education platform, tailored learning materials, and courses aligning with the national curriculum, available in multiple languages and broadcasted through PM e-Vidya DTH channels.
- The certification program includes Canva's design tools training to create engaging lesson plans, infographics, and presentations, emphasizing co-creating content with students and using AI tools for improved classroom outcomes.
- Canva's partnership with NCERT signifies a commitment to advancing digital fluency and creative confidence in classrooms, with Canva aiming to democratize design and creativity at scale in India.
Read Full Article
22 Likes
Analyticsindiamag
1.9k

Image Credit: Analyticsindiamag
Capgemini to Acquire WNS for $3.3 Billion with Focus on Agentic AI
- Capgemini to acquire WNS for $3.3 billion in cash to focus on agentic AI, aiming for global leadership in the field.
- The deal values WNS at $76.50 per share, representing a 28% premium over the 90-day average and a 17% increase over the closing price on July 3.
- The acquisition is expected to boost Capgemini's revenue growth and operating margin, with EPS accretion of 4% by 2026 and 7% post-synergies by 2027.
- The transaction, pending regulatory approvals, is set to close by the end of 2025, strengthening Capgemini's US market presence and offering cross-selling opportunities.
Read Full Article
28 Likes
Medium
50

Image Credit: Medium
YouTube’s AI Search Carousel: How Premium Users Get Smarter Results in 2025
- YouTube has launched an AI-powered search carousel for Premium users in 2025, providing instant video highlights and tailored descriptions for travel or shopping queries.
- The carousel appears for YouTube Premium subscribers in the US when searching for specific topics, presenting a horizontal scroll of short video clips with AI-generated titles and descriptions.
- This feature streamlines the search process by offering quick previews and summaries, making it easier for users to find relevant content without extensive scrolling.
- The AI search carousel acts like a personal travel guide, saving time and facilitating effortless exploration for users managing busy schedules.
Read Full Article
3 Likes
Hackernoon
90
Image Credit: Hackernoon
Time Series Is Everywhere—Here’s How to Actually Forecast It
- Time series data is prevalent in various domains, ranging from stock prices to health monitoring, characterized by data points with timestamps.
- Traditional statistical models like ARIMA and Prophet are effective for basic trends but struggle with noisy, nonlinear, and multivariate data.
- Deep learning techniques, especially LSTMs (Long Short-Term Memory networks), excel at handling time series data with long dependencies and real-world complexities.
- Reinforcement learning, typically used in game AI, can also be applied to time series forecasting for making decisions like stock trading.
Read Full Article
5 Likes
Medium
172

Image Credit: Medium
Python for Data Science, AI & Development — Not Just a Language, It’s an Operating System for…
- Python is more than just a programming language, it's about building scalable ideas and bridging data with decisions.
- Learning Python involves a mindset shift, focusing on building solutions tailored to individual needs.
- Python enables users to create efficient logic and functions, resulting in personalized problem-solving approaches.
- Understanding Python transforms coding into a deliberate process, leading to the development of robust data ecosystems and sustainable systems.
Read Full Article
10 Likes
For uninterrupted reading, download the app