A naukri.com initiative
Data Science News
Feedspot
326
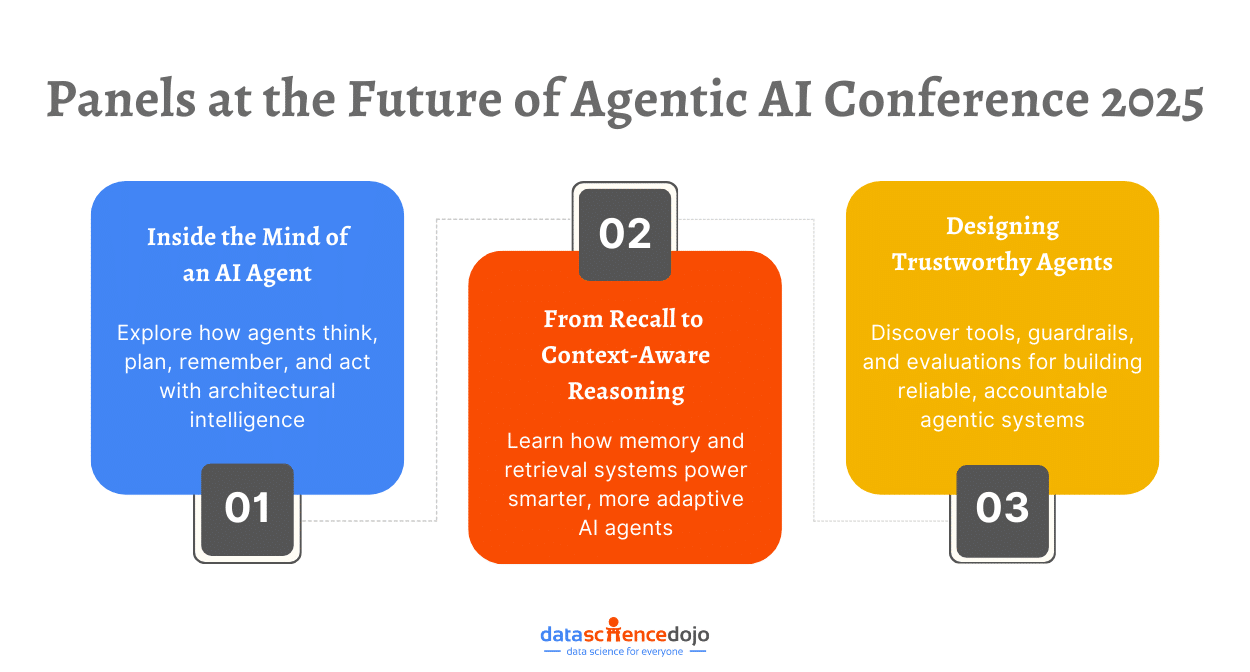
Image Credit: Feedspot
What is an AI Agent? Navigate the Future of Agentic AI with the 2025 Conference Panels
- AI agents are evolving into true collaborators in work and innovation, not just followers.
- The 2025 conference delves into agentic AI systems' planning, memory, and tool usage.
- It explores retrieval mechanisms, memory types, and ensuring safety and transparency in AI.
- Agentic systems learn, adapt, and act like humans, shaping the future of intelligent technology.
Read Full Article
19 Likes
Feedspot
394
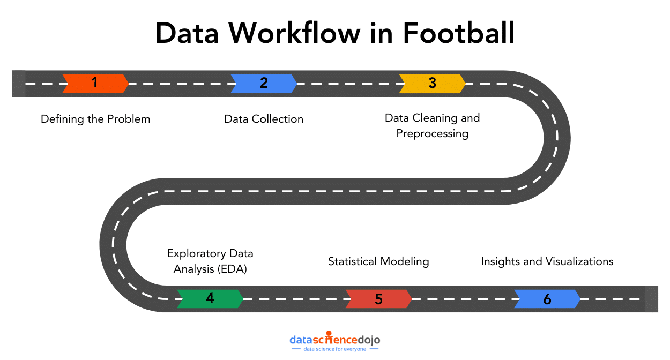
Image Credit: Feedspot
Data Workflows in Football Analytics: From Questions to Insights
- Data workflows play a crucial role in optimizing football team performance through insights.
- From defining problems to data collection, cleaning, and analysis, workflows help identify solutions.
- Combining event and player data, tracking technologies, and statistical modeling enhance performance outcomes.
- Effective communication of actionable insights through dashboards and reports drives on-field improvement.
Read Full Article
23 Likes
Feedspot
132

Image Credit: Feedspot
LLM Observability and Monitoring: The Key to Building Reliable and Secure AI Applications
- LLM observability and monitoring are crucial for building reliable and secure AI applications.
- Failure in AI systems like Air Canada's inaccurate chatbot highlights the importance.
- Monitoring tracks LLM performance while observability digs deeper to explain issues in production.
- Observability tools trace root causes, improve security, and optimize costs for AI systems.
Read Full Article
8 Likes
Feedspot
149

Image Credit: Feedspot
What Is Agentic AI? A Gateway to Building Smarter and Autonomous Agents
- Agentic AI enables machines to independently set goals, make decisions, and adapt in real time.
- It moves beyond automation towards thinking, learning, and acting like humans, faster and autonomously.
- Industries benefit from agentic AI in complex situations, scalability, error reduction, fairness, and 24/7 operations.
- Challenges in designing agentic AI include balancing autonomy, handling biases, unpredictable environments, and ensuring accountability.
- The future of agentic AI requires alignment with human values, ethics, safety, and continuous evolution.
Read Full Article
8 Likes
Feedspot
100
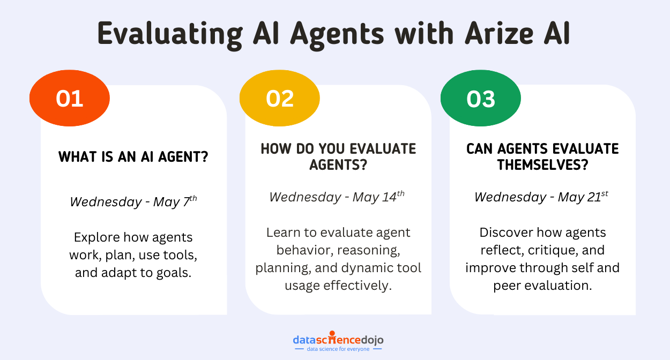
Image Credit: Feedspot
Evaluating AI Agents with Arize AI – A Complete Series to Get You Started!
- AI agents, once a sci-fi concept, are now a tech reality.
- Arize AI introduces new methods to evaluate evolving AI agents.
- These agents use memory, make decisions, and collaborate, challenging evaluation metrics.
- Understanding AI agents involves recognizing their unique features and architectures.
- Evaluation techniques like path-based reasoning and convergence measurement are crucial.
Read Full Article
6 Likes
Analyticsindiamag
169

Image Credit: Analyticsindiamag
Why Cluely Thinks ‘Cheating’ Is the Future of Work
- Cluely, the AI cheating assistant platform, specializes in narratives for cheat situations.
- By hiring influencers over traditional marketing channels, Cluely has a unique growth strategy.
- The startup, known for aiding in job interviews and meetings, embraces being labeled a 'cheating app'.
- Cluely uses AI to provide real-time assistance and aims to become a dominant provider.
Read Full Article
10 Likes
Medium
363

Image Credit: Medium
How YouTube’s Revolutionary AI-Powered Search Carousel is Transforming Content Discovery
- YouTube’s AI-powered search carousel revolutionizes content discovery for Premium users by providing tailored video clips with AI-generated descriptions based on search queries.
- The feature streamlines video search, offering users targeted clips instead of requiring them to sift through numerous videos, enhancing search efficiency and accuracy.
- The AI search carousel's impact is evident in scenarios such as finding specific product reviews like noise-cancelling headphones or gathering travel tips, where it delivers precise and relevant results quickly.
- This AI-driven tool marks a significant shift in how users engage with video content, particularly benefiting Premium subscribers through personalized and efficient video discovery.
Read Full Article
21 Likes
Analyticsindiamag
259

Image Credit: Analyticsindiamag
Why Engineers are Rejecting Indian IT Offer Letters
- Indian IT firms like TCS, Infosys are facing rejection from engineers due to multiple reasons.
- Disillusioned freshers, mid-level engineers, and lateral hires cite discriminatory practices and work challenges.
- Shrinking bench sizes, delayed onboarding, stagnant salaries, and increased workload contribute to dissatisfaction.
Read Full Article
15 Likes
Medium
331

Why Fully Homomorphic Encryption (FHE) Could Be the Future of Blockchain — and How Zama Is…
- Fully Homomorphic Encryption (FHE) allows computations on encrypted data without needing to decrypt it first.
- Zama, a French startup, is working on open-source infrastructure to make FHE usable for developers in web3 applications.
- The combination of blockchain and FHE offers potential use cases like private DeFi, healthcare on-chain, private voting, and decentralized identities.
- Zama's tools, like fhEVM, enable developers to build privacy-preserving decentralized applications without entirely changing their tech stack.
Read Full Article
19 Likes
Medium
218

Image Credit: Medium
Mastering Hypothesis Testing: A Comprehensive Guide for Beginners
- Hypothesis testing is a method used to determine if data provides enough evidence to reject an assumption about a population parameter.
- Key components include steps in hypothesis testing, significance level (α), type I and type II errors, one-tailed vs. two-tailed tests, and common hypothesis testing methods.
- Hypothesis testing involves comparing means of two independent groups, two related samples, expected vs. observed categorical frequencies, and analyzing the relationship between categorical variables.
- Understanding hypothesis testing principles, assumptions, and application is crucial for making data-driven decisions in various fields, from web development to machine learning.
Read Full Article
13 Likes
Medium
169

Image Credit: Medium
Building Smart Search: How Embeddings and kNN Make Search Feel Human
- Smart search systems use embeddings and kNN search to understand human intent and provide accurate results.
- Embeddings translate words into numbers to capture their meaning, enabling computers to comprehend user queries better.
- The combination of embeddings and kNN search facilitates semantic search, allowing retrieval of semantically similar documents efficiently.
- The system leverages Elasticsearch with dense vector fields and HNSW for fast and accurate kNN searches, improving search performance at scale.
Read Full Article
10 Likes
Analyticsindiamag
32

Image Credit: Analyticsindiamag
China Throws a Wrench in India’s iPhone Ambitions
- Amid tensions between China and India, Foxconn reduces presence in Indian iPhone factories.
- Shift towards India in iPhone production hampers China's efforts to undermine Apple.
- China's refusal to export machinery to India poses challenges for Apple's expansion plans.
- Apple seeks to reduce dependence on China by focusing on India for iPhone assembly.
Read Full Article
1 Like
TechBullion
125

Image Credit: TechBullion
Rahman Shittu: The Data Science Powerhouse Redefining Innovation in the US and Beyond
- Rahman Shittu, a data powerhouse, redefines innovation in US and globally.
- His journey from Nigeria to pursuing data science reshapes sectors worldwide.
- Research on healthcare, e-commerce, cybersecurity, and smart cities show global impact.
- Rahman's work blends technical expertise with ethical responsibility for a brighter future.
Read Full Article
7 Likes
Medium
235
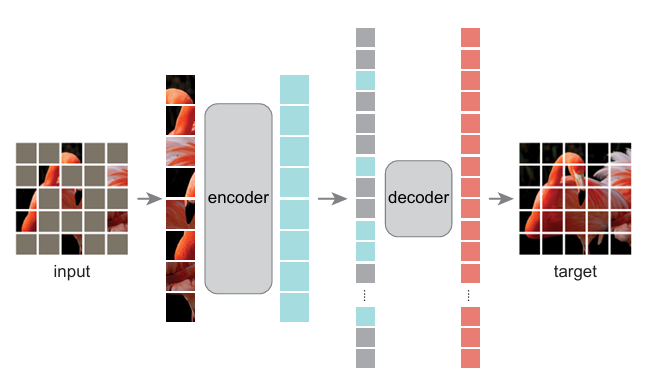
Image Credit: Medium
Masked Autoencoders (MAE): The Art of Seeing More by Masking Most & PyTorch Implementation
- Masked Autoencoders (MAE) scale vision understanding by hiding most of the input image.
- MAE randomly masks 75% of image for model to reconstruct missing pixels efficiently.
- MAE introduces asymmetric setup with strong encoder and small decoder for efficient training.
- MAE's pretraining helps massive models like ViT-H generalize well with ImageNet-1K.
Read Full Article
14 Likes
Medium
268

Image Credit: Medium
The Explosion Didn’t Break Me — It Rewired Me
- The author shares their life story of growing up in Brooklyn, joining the Marine Corps after 9/11, and suffering a traumatic brain injury during combat.
- Despite challenges like injuries, depression, and struggles with brain injury, the author found strength in their leadership qualities and determination to keep going.
- The author pursued education in Computer Science, achieved academic success, and focused on bioinformatics and AI projects, aiming to stay ahead in technology.
- Inspired by their journey, the author founded Crayons to Creators (C2C), emphasizing mentorship, leadership, and community while working on a PhD in veterans' health and military transition.
Read Full Article
16 Likes
For uninterrupted reading, download the app