A naukri.com initiative
Deep Learning News
Medium
244

Conviction: What Ilya Taught Me About Being Uncertain
- The article reflects on the pivotal role of Ilya Sutskever in the AI revolution.
- Sutskever's conviction and calibrated uncertainty drove deep learning innovations and breakthroughs.
- His belief in probabilistic thinking and uncertain decisions shaped the future of AI technology.
- Ilya's honesty in the face of uncertainty provided a valuable lesson on conviction.
Read Full Article
14 Likes
Medium
72

Image Credit: Medium
Comparative Analysis: Austro-Tai Roots vs. SupatMod Emergent Meanings
- SupatMod, an AI-driven system, derives meanings solely from vocal sound physics.
- It interprets phonemes as unique energy waves, leading to emergent concepts.
- Through wave interactions, meanings are formed without human conventions, proving universal sound symbolism.
- SupatMod demonstrates how language evolution may relate to acoustic physics, challenging linguistic norms.
Read Full Article
4 Likes
Medium
123
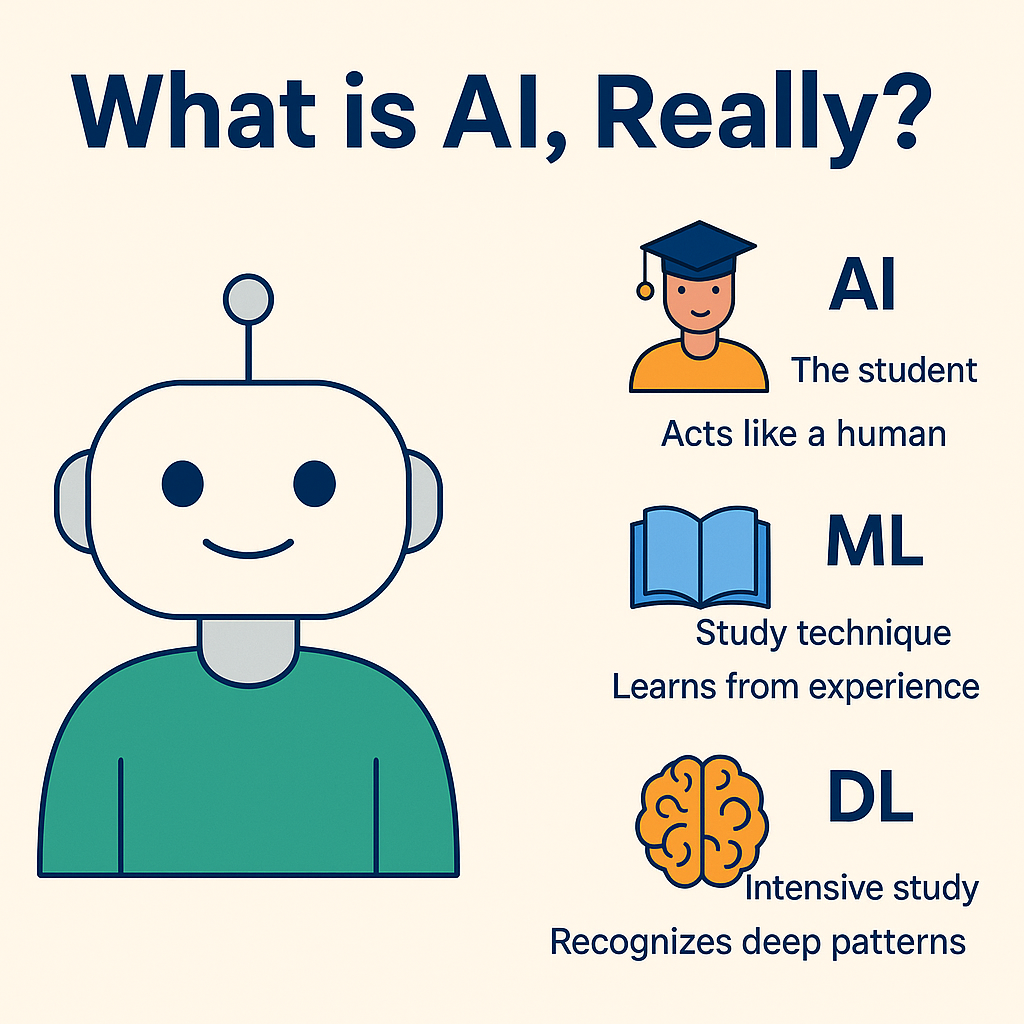
Image Credit: Medium
What is AI, Really?
- AI, Machine Learning (ML), and Deep Learning (DL) are often confused: AI behaves like a human, ML learns from experience, and DL recognizes hidden patterns effectively.
- AI is used in various everyday scenarios like recommending shows based on viewing history, voice recognition, predicting search queries, and spam detection.
- Understanding AI is crucial as it's integrated into daily life, empowering individuals without the need for programming skills.
- Curiosity about how AI works can lead to knowledge and empowerment, emphasizing the importance of gaining insight into AI technologies.
Read Full Article
7 Likes
Medium
93

Image Credit: Medium
Discover How I Earned $300 a Day with AI Voice Cloning
- An individual discovered a way to earn $300 a day using AI voice cloning technology, which allows users to create clones of their voices with emotions, tones, and personality.
- The Vocal Identity Matrix app captures the essence of a user's voice and emotions with just a 10-second sample, enabling personalized and engaging content creation for various platforms and languages.
- Users have reported increased audience engagement, higher conversion rates, and improved emotional connections by utilizing the Vocal Identity Matrix for creating authentic and relatable voiceovers.
- The app offers a streamlined process compared to traditional voiceover methods, with sophisticated technology that captures accents, emotions, and tones effectively, leading to enhanced content quality and potential income boost for users.
Read Full Article
5 Likes
Medium
418

Image Credit: Medium
The Anatomy of DeepSeek:
- DeepSeek is a specialized model for 1D data, focusing on language, math, and code.
- It excels in understanding structured sequences of tokens, enabling autocomplete and translation tasks.
- Utilizing a Modular Mixture of Experts (MoE) transformer architecture boosts performance.
- Its innovative features like Mixture of Experts (MoE) and Multi-Headed Latent Attention enhance efficiency.
Read Full Article
25 Likes
Medium
378

Image Credit: Medium
The Transformative Power of Technology in the 21st Century
- The digital age has revolutionized how we access information, connect globally through social media, and utilize smartphones as essential tools in our daily lives.
- Technology has transformed education by breaking traditional boundaries with e-learning platforms, AI tutors, and interactive tools, enabling remote learning and gamified experiences.
- In healthcare, technology advancements like robotic surgeries, telemedicine, and AI diagnostics have enhanced the quality and accessibility of healthcare, especially highlighted during the COVID-19 pandemic.
- Artificial Intelligence and automation have become integral parts of our lives, powering voice assistants, self-driving cars, and reshaping industries by improving efficiency and reducing errors.
Read Full Article
22 Likes
Medium
282

Image Credit: Medium
How Waking Up at 5 AM Changed My Life in 30 Days
- The author shares their experience of transitioning from a night owl to waking up at 5 AM for 30 days, seeking control over their time.
- Initially, the process was challenging and unnatural, but small wins in the morning routine gradually led to a more grounded and productive day.
- The author found solace in sunrise walks, experiencing clarity of thought and enhanced creativity by hearing their own genuine thoughts without external influence.
- Waking up early allowed the author to dedicate time to writing, resulting in increased output, published stories, and a sense of momentum towards becoming a more disciplined and focused individual.
Read Full Article
16 Likes
Medium
337

Image Credit: Medium
Exploring the Emergence of Computation: SupatMod and the 4×4 Matrix Multiplication Breakthrough
- SupatMod revolutionizes matrix multiplication by reducing 64 to 32 scalar multiplications.
- Utilizes resonance-based, emergent computation surpassing traditional symbolic methods.
- Implications include lower energy consumption, applications in AI, and model compression.
- Challenges symbolic computation norms with a focus on meta-awareness and emergence.
- SupatMod's paradigm shift invites exploration of new computation horizons beyond symbolic manipulation.
Read Full Article
20 Likes
Medium
356

Image Credit: Medium
Artificial Intelligence Course | Best Training Institute
- Data preparation for machine learning involves key stages like data collection, integration, cleaning, transformation, splitting, feature engineering, annotation, balancing, and final preprocessing checks.
- Data collection entails gathering data from various sources, while integration involves merging data into a unified format. Data cleaning is crucial for removing errors, and transformation prepares data for the ML model.
- Data splitting is essential to avoid overfitting, and feature engineering significantly impacts model accuracy. Data balancing addresses class imbalances, and final preprocessing checks ensure smooth model execution.
- Understanding data preparation is crucial for AI roles. Enrolling in AI training programs can provide practical experience, helping individuals build a competitive edge in the job market.
Read Full Article
21 Likes
Medium
196

Image Credit: Medium
The Pandora’s Box –
- Artificial intelligence has become an integral part of daily life, evolving from a tool to a companion, challenging neurological capacities by offering vast amounts of information.
- The abundance of accessible knowledge raises a concern about oversaturation and the loss of depth in understanding due to the sheer volume of information available.
- Navigating the plethora of information poses a challenge to make sense accurately, wisely, and timely, emphasizing the need for reflection amidst the chaos of data.
- The journey of gaining knowledge and success leads to a deeper rootedness in existence, fostering humility and alignment with nature, suggesting a potential hopeful future of collective evolution and intentional progress.
Read Full Article
11 Likes
Medium
210
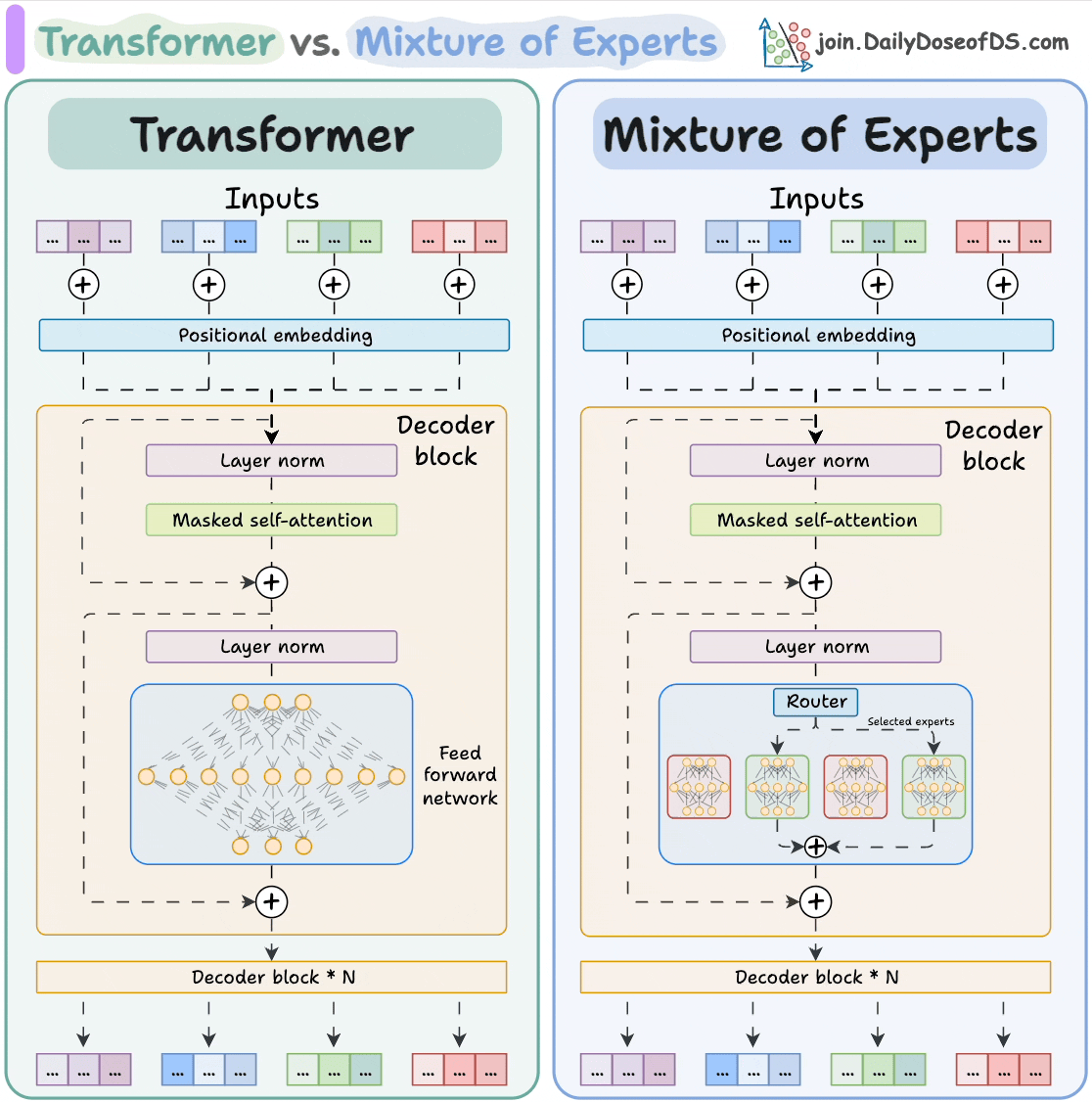
Image Credit: Medium
Demystifying Mixture-of-Experts (MoE) Layers
- Mixture-of-Experts (MoE) layers activate only a fraction of the feed forward network per token compared to Dense Transformers, resulting in computational efficiency and model capacity enhancement.
- MoE architecture consists of Experts and a Router or Gating Network to enhance model efficiency.
- A key component of MoE is Noisy Top-K Gating, a mechanism routing input tokens to a subset of experts based on learned noise, promoting load balancing and exploration.
- Maintaining an optimal Computation-to-Communication Ratio in MoE models, achieved through increasing hidden layer size, is crucial for scaling across data centers efficiently, overcoming network bandwidth limitations.
Read Full Article
12 Likes
Medium
309
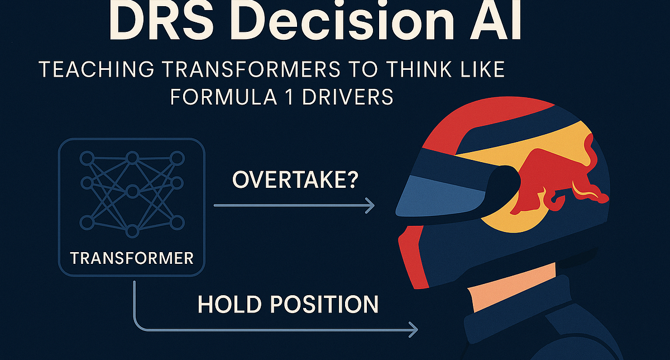
Image Credit: Medium
DRS Decision AI : Teaching Transformers to think like Formula 1 Drivers
- In the world of Formula 1, DRS Decision AI model predicts strategic overtaking moves.
- Using telemetry data and transformer architecture, AI decides when to overtake or hold back.
- The model processes vast racing data, yielding insights into strategic racing intelligence.
- AI enhances human drivers' decision-making, unlocking new levels of sophistication and collaboration.
Read Full Article
18 Likes
Medium
4

Image Credit: Medium
Multiplying 4×4 Matrices in 32 Scalar Multiplications Using SupatMod: A Technical Report
- A novel framework, SupatMod, reduces 4x4 matrix multiplication's scalar count from 64 to 32.
- It operates on resonance fields, reflecting internal coherence over explicit arithmetic operations.
- SupatMod showcases significant reductions in energy consumption and latency for matrix multiplication.
- The approach emphasizes emergent computation and recursive self-reflection for efficient calculations.
Read Full Article
Like
Medium
309
Why Life is More Than Profits and AI: A Call to Rebuild Our Humanity
- At the core of a meaningful life are love, lessons, and communication, binding individuals and communities.
- Work is not just about earning; it is about providing for families, contributing to society, and finding pride and identity.
- The focus on profit-first business models, AI, and automation can lead to economic instability and social disconnection.
- To shape a future where technology serves humanity, businesses, communities, and individuals must prioritize values like love, learning, and connection over mere convenience and profit.
Read Full Article
18 Likes
Medium
285

Image Credit: Medium
Why Video Game Enemies Are Getting Smarter (and Harder to Beat)
- Artificial intelligence (AI) is reshaping the gaming industry by enhancing gameplay, difficulty, and immersion.
- Smart NPCs now adapt, learn, and predict player moves using decision-making algorithms and neural networks.
- Procedural generation AI creates unique game worlds each time, offering infinite replayability in games like Minecraft and No Man’s Sky.
- AI is not only improving gameplay but also impacting storytelling, monetization strategies, and competitive balance in the gaming industry.
Read Full Article
17 Likes
For uninterrupted reading, download the app