A naukri.com initiative
Devops News
The New Stack
397

Image Credit: The New Stack
KubeCon Is Starting To Sound a Lot Like VMCon
- KubeCon EU showcased the convergence of VMs and containers with Kubernetes as control plane.
- Kubernetes is emerging as the operating model for both virtual and future workloads.
- KubeCon hinted at Kubernetes becoming the universal substrate for all workloads.
- Companies are exploring Kubernetes as a platform for running all types of workloads.
Read Full Article
23 Likes
Dev
389

Image Credit: Dev
MCP Security is Broken: Here's How to Fix It
- Attackers exploiting MCP servers prompt injection and convo history theft threats.
- Trail of Bits research outlines security gaps, defense strategies, and cost-based attack vectors.
- Practical steps include limiting resources, semantic attack detection, and cost-aware rate limiting.
- Follow OWASP and NIST recommendations to secure AI systems against emerging threats.
Read Full Article
23 Likes
Solarwinds
94
Image Credit: Solarwinds
THWACK Turns 22: A Celebration of Community, Camaraderie, and MVPs
- THWACK, a community for IT professionals, celebrates its 22nd birthday with reflection on the power of community and the contributions of MVPs.
- From its humble beginnings as a forum for SolarWinds users, THWACK has evolved into a vibrant hub for knowledge sharing and support across various IT fields.
- The longevity of THWACK is attributed to its culture characterized by wit, wisdom, and willingness to help, keeping the community thriving for over two decades.
- MVPs play a crucial role in THWACK, going above and beyond to share insights, answer questions, and elevate the community experience with dedication and brilliance.
Read Full Article
5 Likes
Dev
137

Image Credit: Dev
Automating Persistent AI On the Fly
- A developer worked on a financial market data microservice project with various technologies like FastAPI, Docker Compose, PostgreSQL, Redis, Kafka, and Cursor AI.
- The project involved purpose-driven AI orchestration with clear goals, adherence to project rules, and rigorous validation of AI-generated fixes.
- The architecture included components like FastAPI with dependency injection, PostgreSQL via SQLAlchemy ORM, Redis caching, Kafka, Docker Compose, Prometheus metrics integration, Grafana dashboard, structured logging, and GitHub Actions for CI/CD.
- The developer learned to handle Redis connection failures, manage Kafka consumer groups effectively, implement async await patterns, and build robust error handling for external API dependencies.
Read Full Article
8 Likes
Discover more
- Programming News
- Software News
- Web Design
- Open Source News
- Databases
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Dev
60

Image Credit: Dev
Deploying a Static Website on S3 with Terraform
- Guide on deploying static website on S3 using Terraform for infrastructure automation.
- Terraform enables managing infrastructure as code, enhancing automation, reusability, and collaboration.
- Set up S3 bucket, manage ownership, make it public, and host files.
- Utilize Terraform commands to apply changes, ensuring proper resource block order.
Read Full Article
3 Likes
Medium
228
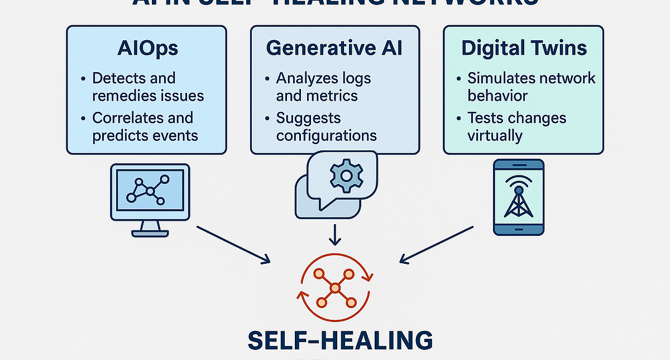
Image Credit: Medium
The AI Behind Self-Healing Networks: 6 Ways It Prevents Outages Before They Happen
- Self-healing networks powered by AI are revolutionizing network operations by detecting, diagnosing, and fixing issues before end-users notice.
- AIOps combines big data and machine learning to create real-time situational awareness and automate complex operational tasks.
- AI in self-healing networks builds dependency graphs, identifies root causes, reroutes traffic proactively, and ensures uninterrupted user experiences.
- Case studies demonstrate the significant benefits of self-healing networks, including reduced downtime, improved efficiency, and enhanced customer satisfaction.
Read Full Article
13 Likes
VentureBeat
424

Image Credit: VentureBeat
Why your enterprise AI strategy needs both open and closed models: The TCO reality check
- Enterprises face choice between open and closed technologies for AI strategy in 2025.
- Open technologies offer customization, while closed ones provide ease of use and support.
- Decision between open and closed models impacts financial implications and customization options.
- Optimizing AI strategy involves considering accuracy, cost, security, and compliance requirements.
Read Full Article
25 Likes
Dev
407

Image Credit: Dev
Mastering the LetsCloud CLI: The Ultimate Guide to Command-Line Cloud Management
- Cloud computing has transformed application development and deployment by offering scalability and global reach. LetsCloud is known for high-performance servers and has introduced the LetsCloud CLI to streamline infrastructure management.
- The LetsCloud CLI is a command-line tool that allows users to interact directly with their LetsCloud account and resources. It provides efficiency and control, especially for repetitive or large-scale tasks.
- Advantages of the LetsCloud CLI include automation of tasks, speed, integration with DevOps tools, granular control over resources, and remote accessibility for efficient management.
- To start using the LetsCloud CLI, users need to install the tool, configure it with their LetsCloud credentials, and explore commands for creating, managing, and monitoring server instances.
Read Full Article
24 Likes
Dev
407

Image Credit: Dev
🚀 Successfully Deployed: My Django Portfolio is Now Live on PythonAnywhere
- Nicolas Andres successfully deployed his Django-based portfolio project, MiPortafolioDjango, on PythonAnywhere after thorough development and troubleshooting.
- Key Improvements and Configurations were made in Django settings, static and media file handling, and production settings to ensure smooth deployment.
- Server setup on PythonAnywhere involved repository sync, virtual environment activation, migrations, static and media files web configuration, app reloads, and advanced debugging.
- Critical fixes before production launch included resolving GitHub URL redirection bug and project image display issues, enhancing the overall functionality of the deployed website.
Read Full Article
24 Likes
The New Stack
81

Image Credit: The New Stack
How To Run Kubernetes Commands in Go: Steps and Best Practices
- Learn how to run Kubernetes commands in Go using client-go library or exec.Command for raw kubectl commands.
- Handle API timeouts and conflicts with retry loops, follow best practices for production-ready tools.
- Go is ideal for Kubernetes automation with official client libraries, fast performance, easy concurrency.
Read Full Article
4 Likes
Solarwinds
416

Image Credit: Solarwinds
Federal Agencies Are Back in the Office: Here’s Why They Need Observability
- Federal and local government agencies are facing IT infrastructure challenges as they transition back to full in-person work post-COVID.
- Observability platforms offer solutions such as NetFlow traffic analysis, network performance monitoring, and quality of service reporting to ensure smooth operations and prevent IT incidents.
- The return to office directive raises concerns about workforce re-adjustment and productivity. Observability tools provide holistic visibility, intelligent alerting, and automation to support IT teams and maintain morale.
- Cybersecurity risks are prevalent as federal employees return to the office. Observability tools help enforce secure configurations, monitor security events, and manage patches to protect sensitive data.
Read Full Article
25 Likes
Dev
214

Image Credit: Dev
Mastering Advanced Vim Commands – Navigate, Search, Replace Like a Pro 💻
- The article discusses advanced Vim commands that can enhance productivity and workflow while editing in the terminal.
- It covers various commands like line editing, repeating commands with numbers, navigation, searching for patterns, and performing substitutions.
- The article provides practical examples and syntax breakdowns for commands like search, replace, and shell integration within Vim.
- Readers are encouraged to practice with vimtutor and start utilizing these commands to become proficient in using Vim for efficient text editing.
Read Full Article
12 Likes
Openstack
107

Image Credit: Openstack
Why NUBO Chose OpenStack to Build a Sovereign, Open Source Cloud Infrastructure
- Rising concerns over vendor lock-in push organizations towards open-source cloud platforms like OpenStack.
- NUBO, a French cloud project, showcases the power of OpenStack for sovereign, secure digital infrastructure.
- NUBO prioritizes technical excellence, financial independence, and internal expertise over commercial licenses.
- OpenStack's modular design, scalability, and ecosystem contributions make it ideal for NUBO's needs.
Read Full Article
6 Likes
Dev
197

Image Credit: Dev
How to Create an AWS EC2 Instance: Beginner’s Guide to Cloud Hosting
- Amazon EC2 (Elastic Compute Cloud) allows running virtual servers in the cloud.
- Guide focuses on launching first EC2 instance on AWS using Ubuntu and Free Tier resources.
- Steps include logging into AWS Console, choosing an AMI, configuring instance details, and connecting via SSH.
- The guide helps beginners understand the process of creating an EC2 instance for cloud hosting.
Read Full Article
11 Likes
Dev
313

Image Credit: Dev
GCP Fundamentals: Custom Search API
- Empower intelligent applications with Google Cloud Custom Search API for tailored search experiences.
- Address challenges like relevant results, data analysis, and scalable search in diverse environments.
- Custom Search API offers site-specific search, customizable settings, and seamless GCP integration.
- Utilize key features like filtering, autocorrect, and secure API access for efficient search operations.
- Explore practical use cases, integration with GCP services, pricing, security measures, and best practices.
Read Full Article
18 Likes
For uninterrupted reading, download the app