A naukri.com initiative
Neural Networks News
Medium
364

Image Credit: Medium
Transformer Titans Architecture: Reimagining Attention from Fundamentals
- Memory is a fundamental mental process essential for human learning, without which basic reflexes and behaviors would dominate.
- Current AI models exhibit a broken memory system, requiring every word to interact with every other word in a sentence, leading to inefficiencies.
- The quadratic computational complexity of AI attention mechanisms poses significant limitations as sequence length increases, hindering efficient processing.
- The existing AI design flaw contradicts human cognitive processes, where individuals do not consciously analyze every past thought while reading.
Read Full Article
21 Likes
Hackernoon
207

Image Credit: Hackernoon
Accelerating Neural Networks: The Power of Quantization
- Quantization is a powerful technique in machine learning to reduce memory and computational requirements by converting floating-point numbers to lower-precision integers.
- Neural networks are increasingly required to run on resource-constrained devices, making quantization essential for efficient operation.
- Quantization involves compressing the range of values to reduce data size, speed up computations, and enhance efficiency.
- Weights and activations in neural networks are commonly quantized to optimize model size, speed, and memory requirements.
- Symmetric and asymmetric quantization are two main approaches, each with specific use cases and benefits.
- In asymmetric quantization, zero point defines which int8 value corresponds to zero in the float range.
- Implementation in PyTorch involves converting tensors to int8, calculating scale and zero point, and handling quantization errors.
- Post-training symmetric quantization allows converting learned float32 weights to quantized int8 values for efficient inference.
- Quantization significantly compresses models while maintaining numerical accuracy for practical tasks.
- Quantization enables neural networks to operate efficiently on edge devices, offering smaller models and faster inference times.
Read Full Article
12 Likes
Medium
144

Image Credit: Medium
Starting My Machine Learning Journey: Why I’m Learning in Public
- The author is starting their machine learning journey and is excited about building something cool using ML, like an app that predicts memes or tunes music to your mood.
- They believe that understanding ML requires math and code, so they are focusing on object-oriented programming and plan to dive into Stanford's courses on AI concepts and reinforcement learning.
- They plan to create beginner-friendly content to give back to the community and find learning in public more enjoyable than learning alone.
- The blog will contain messy, honest, and helpful posts about tools, resources, mindsets, and the journey of learning ML, inviting others to join them on this learning path.
Read Full Article
8 Likes
Medium
95
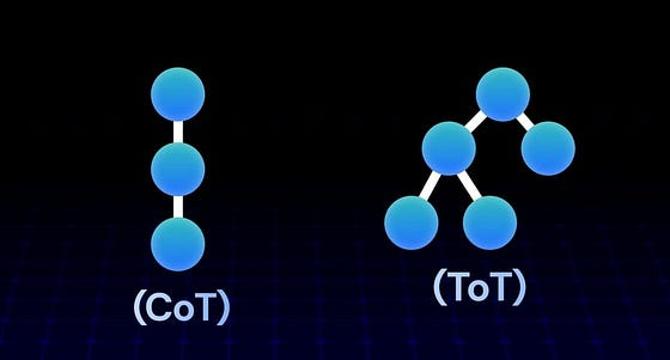
Image Credit: Medium
Chain of Thought vs. Tree of Thought: How AI is Learning to Think Like Humans
- Chain of Thought (CoT) and Tree of Thought (ToT) prompting are techniques designed to help AI think before answering.
- CoT allows AI to reason step-by-step, improving accuracy for math, logic, and multi-step tasks.
- Tree of Thought enables the model to explore multiple reasoning branches, score them, and choose the best path forward.
- Future iterations may involve experimenting with Tree of Thought to allow the model to explore multiple query interpretations and select the most accurate one.
Read Full Article
5 Likes
Medium
408

Introduction to Neural Networks: A Visual & Intuitive Guide
- Neural networks are explained using visuals, analogies, and real-world intuition in this guide to demystify their working and showcase their power.
- Nodes in each layer of a neural network act as mini calculators, adding non-linearity crucial for learning complex patterns mathematically.
- By repeatedly processing data over many layers, neural networks adjust until reaching prediction perfection, unveiling deeper abstract understanding.
- While they can be hard to interpret compared to other models, neural networks play a vital role in various applications like recommendation engines, chatbots, and computer vision apps.
Read Full Article
24 Likes
Medium
390
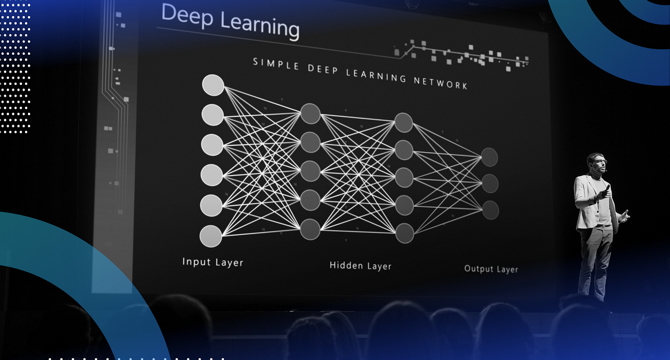
Image Credit: Medium
Deep Learning: From Fundamentals to Advanced Concepts
- Deep learning is a branch of AI that automatically extracts features from raw data through multiple layers of abstraction using neural networks inspired by the human brain's structure.
- Key types of neural networks include Feedforward Neural Networks, Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformers, each designed for specific data types like images or sequential data.
- Common challenges in deep learning are underfitting and overfitting, with solutions like transfer learning, Generative Adversarial Networks (GANs), self-supervised learning, attention mechanisms, and Explainable AI (XAI) to improve model performance and interpretability.
Read Full Article
23 Likes
Semiengineering
263

Image Credit: Semiengineering
Energy-Aware DL: The Interplay Between NN Efficiency And Hardware Constraints (Imperial College London, Cambridge)
- A technical paper titled “Energy-Aware Deep Learning on Resource-Constrained Hardware” was published by researchers at Imperial College London and University of Cambridge.
- The paper discusses the utilization of deep learning on IoT and mobile devices as a more energy-efficient alternative to cloud-based processing, highlighting the importance of energy-aware approaches due to device energy constraints.
- The overview in the paper outlines methodologies for optimizing DL inference and training on resource-constrained devices, focusing on energy consumption implications, system-level efficiency, and limitations in terms of network types, hardware platforms, and application scenarios.
- Authors of the paper are Josh Millar, Hamed Haddadi, and Anil Madhavapeddy, and it is published on arXiv under the code 2505.12523, dated May 2025.
Read Full Article
15 Likes
Medium
82
Image Credit: Medium
AI == Math model of the human brain
- Human evolution has led to the development of a complex brain with over 86 billion neurons.
- The human brain processes sensory inputs through a complex network involving photoreceptor cells, chemical changes, and electrical signals.
- The brain utilizes joint encodings for sensory inputs and can simulate scenarios without external input, akin to AI multimodal and generative models.
- Individual differences in learning and performance in the brain have AI equivalents in model initialization and training hyperparameters.
- The brain's sparse activation is mirrored in AI through techniques like ReLU and dropout for selective activation.
- Plasticity in the brain is akin to AI transfer learning, enabling quick adaptation to new tasks.
- Neural circuits in the brain optimize routes similarly to residual connections in AI for faster information propagation.
- Emotional reactions in the brain have parallels in sentiment analysis and reinforcement learning models in AI.
- Machine learning models learn patterns from data without explicit programming and improve performance by adjusting internal parameters.
- Artificial neural networks draw inspiration from biological neurons, with weighted inputs and learning algorithms adjusting synaptic strengths.
Read Full Article
4 Likes
Medium
14

Image Credit: Medium
Prompt Engineering Demystified: How to Write Prompts That Deliver
- Prompt Engineering is the Art and Science of crafting excellent inputs to guide AI for desired results.
- Individuals can use prompts to turn AI into personal assistants for tasks like drafting emails and planning daily tasks.
- For businesses, prompt engineering enhances productivity, workflow streamlining, data-driven insights, and innovation.
- Effective prompting is a core digital literacy skill that unlocks creativity, accelerates productivity, and provides a competitive advantage.
Read Full Article
Like
Medium
424

Image Credit: Medium
Introducing DARKBOT™: Beyond Neural Networks — A Quantum-Inspired Revolution in AI
- DARKBOT™ introduces a new numerological architecture based on field dynamics for AI.
- It focuses on achieving resonance between fields instead of traditional command-based interactions.
- The hardware evolution involves developing physical substrates optimized for field resonance.
- DARKBOT™ represents a cultural shift towards a more relational understanding of reality, emphasizing the importance of fields and resonance in human-machine interaction.
Read Full Article
25 Likes
Semiengineering
232

Image Credit: Semiengineering
AI Accelerators Moving Out From Data Centers
- AI accelerator development is rapidly evolving, driven by the increasing demand for more computing power and the growing role of chiplets in this space.
- The expansion of AI into cloud, enterprise, and edge environments is fueling the need for diverse systems and structures to accommodate different AI models and applications.
- Companies are exploring a wide range of AI accelerator trends, including larger models, power management through photonics, and the deployment of neural networks in autonomous systems at the edge.
- Flexibility and scalability are key priorities for silicon chip designers to accommodate evolving AI models and applications, with chiplets playing a significant role in enabling modularity and customization.
- Chiplets offer cost efficiency, customization, and configurability in AI accelerators, allowing for better integration of AI components and flexibility in adapting to changing requirements.
- Verification challenges in chiplet-based AI accelerators include addressing latency variations, thermal effects, and ensuring coherency between different components, adding complexity to the design and verification process.
- The industry is moving towards a more modular approach to design with chiplets, where various components can be combined to create customized solutions, leading to a shift in traditional design practices.
- Chiplets have been used for integration challenges in various domains, offering a cost-effective and flexible solution for combining different technologies and components.
- The evolution of AI accelerators and chiplet technology signals a significant shift in semiconductor design practices, introducing new opportunities and challenges to address the increasing compute demands of AI applications.
- The trend towards customization and modularity in AI accelerators is reshaping the semiconductor industry, paving the way for more efficient and adaptable solutions for diverse AI applications.
Read Full Article
14 Likes
Medium
200

Image Credit: Medium
Calculus in Data Science: How Derivatives Power Optimization Algorithms
- Derivatives in data science measure how fast the loss changes in a model's predictions.
- Multivariate calculus helps calculate partial derivatives for adjusting multiple parameters simultaneously.
- Optimization in data science involves moving against the gradient to minimize loss, aided by algorithms like gradient descent.
- Understanding derivatives is crucial for guiding machine learning models to improve gradually and make better predictions.
Read Full Article
12 Likes
Medium
137
Image Credit: Medium
OPENTadpole: the first cybernetic animal
- OPENTadpole is a project aiming to model the nervous system using a simplified approach, starting with animals like tadpoles and worms.
- Inspired by OpenWorm, OPENTadpole focuses on creating a cybernetic animal with an artificial nervous system.
- It references the Blue Brain and Human Brain Projects in simulating brain fragments and neural networks.
- The Human Brain Project aims to model the entire human brain, while OpenWorm simulates the nervous system of C. elegans.
- OPENTadpole uses the Unity game engine to create a virtual tadpole with a simplified nervous system and environment simulator.
- The project explores neural chain generators, modulating synapses, and behavior mechanisms in the tadpole model.
- It simulates swimming, directional movement, food detection, hunger, fatigue, and responses to light and touch in the virtual tadpole.
- By simplifying neural systems and focusing on functional significance, OPENTadpole provides insights into nervous system organization.
- The project demonstrates the modeling of neural behavior using computational resources and principles of nervous system interaction.
- Through simulations, OPENTadpole highlights the flexibility and adaptability of neural networks in controlling complex behaviors.
- By emphasizing simplification and functionality, OPENTadpole showcases a novel approach to modeling nervous system behavior in cybernetic animals.
Read Full Article
8 Likes
Medium
214

Image Credit: Medium
The Future of Marketing Isn’t Louder. It’s Smarter
- Marketing landscape is shifting from louder to smarter strategies.
- Audiences are tuning out due to excessive content and noise in the digital space.
- Smart marketing involves applying intelligence to creativity using data, automation, and AI.
- The focus is on working smarter, not harder, by driving relevance and personalization through technology.
Read Full Article
12 Likes
Hackernoon
343

Image Credit: Hackernoon
AI Might Soon Watch Your Login Attempts the Blade Runner Way
- AI may soon revolutionize authentication and authorization processes by utilizing psychometric analysis to assess users' emotional reactions, behavior patterns, and cognitive habits.
- Psychometric analysis, a subset of psychological analysis, involves methods like the Big Five or MBTI to classify individuals into different personality types, already applied in various fields.
- Researchers have conducted studies to determine people's true feelings and behaviors using computer programs, paving the way for psycho-physiological authentication based on behavior, emotions, and physiological responses.
- Future authentication systems could evaluate users' character, mood, language, and stress reactions for secure and personalized authentication, eliminating the need for traditional passwords and biometric methods.
- To implement such AI-driven authentication, data collection, machine training with neural networks, and multiple layers of verification combining psychological analysis and biometrics are essential.
- Benefits of this system include personalized authentication, enhanced security, and ease of use without conventional password requirements, while potential drawbacks include privacy concerns and resource-intensive infrastructure needs.
- Technological advancements are moving towards incorporating psychological aspects in data analysis, suggesting a potential shift towards deep psychological analysis for secure authentication and access in the future.
- While the concept of deep psychological analysis once seemed futuristic like in Blade Runner, it is gradually being explored for its application in authentication processes, hinting at a future where proving your humanity goes beyond traditional methods.
Read Full Article
20 Likes
For uninterrupted reading, download the app