A naukri.com initiative
Big Data News
Precisely
306

Image Credit: Precisely
Retain Customers with Faster, Friendlier Claims: 4 Strategies for Insurers
- Efficient claims processing and transparent communications are key to customer satisfaction in the insurance industry.
- Longer claim resolution times and inconsistent customer communications can lead to low customer satisfaction in property claims.
- 30% of dissatisfied claimants either switched carriers or were considering doing so, which highlights the importance of improving customer satisfaction in the insurance industry.
- The time it takes to resolve claims, extended repair cycles, and inconsistent communication are major pain points in property claims processing.
- Automating parts of the claims process, providing omnichannel communication, offering personalized support, and adopting a digital-first approach are essential strategies for improving the overall customer experience.
- Insurers that communicate well and provide regular updates on the progress of the claim are more likely to retain customers.
- Empathy and personalization, even within automated processes, are important in creating a positive customer experience.
- Digital self-service tools, automating processes, and improving communication can turn the trend of declining customer satisfaction in the insurance industry around.
- Precisely’s EngageOne solutions can help create a better customer experience by providing seamless and personalized communication throughout the claims journey.
- Improving customer satisfaction is a priority for insurance companies as it directly impacts retention rates and profitability.
Read Full Article
18 Likes
Amazon
137

Image Credit: Amazon
Achieve the best price-performance in Amazon Redshift with elastic histograms for selectivity estimation
- Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
- Amazon Redshift’s advanced Query Optimizer is a crucial part of that leading performance.
- As data is ingested into the Redshift data warehouse over time, statistics could become stale, which in turn causes inaccurate selectivity estimations, leading to sub-optimal query plans that impact query performance.
- Amazon Redshift introduced a new selectivity estimation technique in Amazon Redshift patch release P183 (v1.0.75379) to address the situation — having up-to-date statistics on temporal columns improving query plans and thereby performance.
- The new technique captures real-time statistical metadata gathered during data ingestion without incurring additional computational overhead.
- Amazon Redshift users will benefit with better query response times for their workloads.
- The new selectivity estimation enhancement has already improved the performance of hundreds of thousands of customer queries in the Amazon Redshift fleet since its introduction in the patch release P183.
- Amazon Redshift now offers enhanced query performance with optimizations such as Enhanced Histograms for Selectivity Estimation in the absence of fresh statistics by relying on metadata statistics gathered during ingestion.
- Optimizations are enabled by default and Amazon Redshift is on a mission to continuously improve performance and therefore overall price-performance.
- We invite you to try the numerous new features introduced in Amazon Redshift together with the new performance enhancements.
Read Full Article
8 Likes
Siliconangle
390

Image Credit: Siliconangle
Concentric bags $45M to expand its AI-powered data cataloging tools
- Concentric Inc. has closed a $45 million funding round led by Top Tier Capital Partners and HarbourVest Partners.
- The startup offers an AI-powered data cataloging tool for data access governance.
- Concentric's tool helps companies discover and evaluate their data, identify any data of concern, and provide recommendations for better securing information and ensuring compliance.
- With the funding, Concentric plans to expand its go-to-market strategies and accelerate product development.
Read Full Article
23 Likes
Amazon
160
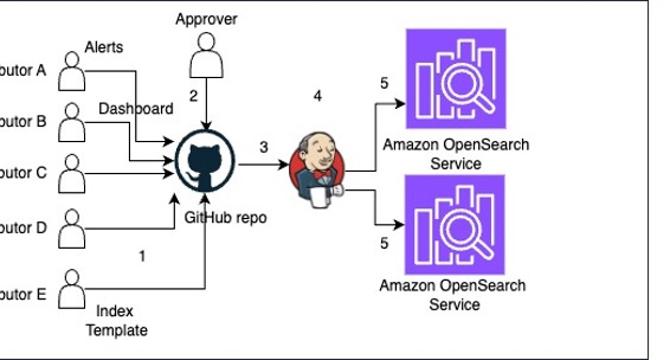
Image Credit: Amazon
Manage Amazon OpenSearch Service Visualizations, Alerts, and More with GitHub and Jenkins
- Amazon OpenSearch Service is a managed service for search and analytics that allows organizations to secure data and explore log analytics.
- This post presents a solution to deploy OpenSearch stored objects using GitHub and Jenkins.
- It is recommended to discourage contributors from making changes directly to the production OpenSearch Service domain and instead implement a gatekeeper process to validate and test the changes before moving them to OpenSearch Service.
- The solution consists of three personas: Contributor, User, and Approver.
- CI/CD automates code integration, testing, and deployment. Faster and more reliable software releases are possible through CI and CD.
- In the post, the author demonstrates how to build a CI/CD pipeline for deploying OpenSearch Service security roles using GitHub and Jenkins.
- Create an AWS Identity and Access Management (IAM) role in AWS for Jenkins before configuring Jenkins.
- Create a GitHub repository to store OpenSearch Service security roles in JSON format.
- Install Python packages and create the Python file on the Jenkins server.
- Finally, push the newly created role file into the GitHub repository and build a job that will create the role in OpenSearch Service domain.
Read Full Article
9 Likes
Precisely
408

Image Credit: Precisely
Data Migration to the Cloud: Benefits and Best Practices
- Cloud migration enhances agility, cuts operational costs, and helps you stay compliant with evolving regulations.
- Maintaining data integrity during cloud migration is essential to ensure reliable and high-quality data for better decision-making and future use in advanced applications.
- Partner with the right providers that offer both technical tools and expertise within your industry and use cases.
- Making the move to the cloud opens the door to new opportunities that benefit businesses of all kinds.
- Migrating your data to the cloud empowers agility on a level that traditional IT infrastructures simply can’t match.
- Cloud migration also supports long-term cost savings by reducing your operational overhead.
- Navigating an increasingly complex regulatory environment is complicated – but cloud migration can help you succeed with greater standardization in your processes.
- To maximize all of the benefits of cloud migration, data integrity needs to be a priority throughout the process.
- Even with the clear advantages, some organizations are still hesitant to migrate data to the cloud.
- Choosing the right partner to guide you through this process will be key to your success.
Read Full Article
24 Likes
Amazon
27

Image Credit: Amazon
Simplify your query performance diagnostics in Amazon Redshift with Query profiler
- Amazon Redshift is a cloud-based data warehouse that lets you analyze data at scale, but it also provides performance metrics and data to monitor its health and performance.
- The Query profiler is a new graphical tool that gives a visual representation of the query’s run order, execution plan, and various statistics that will help users analyze the query performance and troubleshoot it.
- The Query profiler is part of the Amazon Redshift Console, available for both Redshift Serverless and Redshift provisioned clusters dashboard.
- Using the Query profiler, users can identify the root cause of the query slowness and troubleshoot long-running queries effectively.
- Amazon Redshift provides two categories of performance data that helps monitor database activity, inspect and diagnose query performance problems; Amazon CloudWatch Metrics and Query and Load Performance Data.
- This article provides a step-by-step approach to analyze and troubleshoot longer running queries using the Query Profiler for two use cases: Nested loop joins and Suboptimal data distribution.
- To avoid unwanted costs, dropping all tables in sample_data_dev under tpcds schema is necessary after completing the steps for Query Profiler.
- The Query profiler displays information returned by SYS_QUERY_HISTORY, SYS_QUERY_EXPLAIN, SYS_QUERY_DETAIL, and SYS_CHILD_QUERY_TEXT views.
- Queries run by Query profiler to return the query information run on the same data warehouse as the user-defined queries.
- The authors of the article demonstrate how Query profiler can be used to monitor and troubleshoot long-running queries, recommends users try this feature and share feedback with AWS.
Read Full Article
1 Like
Amazon
87

Image Credit: Amazon
Introducing simplified interaction with the Airflow REST API in Amazon MWAA
- Today, we are excited to announce an enhancement to the Amazon MWAA integration with the Airflow REST API.
- The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines.
- Amazon MWAA now supports a simplified mechanism for interacting with the Airflow REST API using AWS credentials, significantly reducing complexity and improving overall usability.
- The new InvokeRestApi capability allows you to run Airflow REST API requests with a valid SigV4 signature using your existing AWS credentials.
- The simplified REST API access enables automating various administrative and management tasks, such as managing Airflow variables, connections, slot pools, and more.
- The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events.
- Using the dataset-based scheduling feature in Airflow, the enhanced API enables the Amazon MWAA environment to manage the incoming workload and scale resources accordingly, improving the overall reliability and efficiency of event-driven pipelines.
- This new capability opens up a wide range of use cases, from centralizing and automating administrative tasks, improving overall usability, to building event-driven, data-aware data pipelines.
- By using the new InvokeRestApi, you can streamline your data management processes, enhance operational efficiency, and drive greater value from your data-driven systems.
- The enhanced integration between Amazon MWAA and the Airflow REST API represents a significant improvement in the ease of interacting with Airflow’s core functionalities.
Read Full Article
5 Likes
Amazon
45

Image Credit: Amazon
How Getir unleashed data democratization using a data mesh architecture with Amazon Redshift
- Getir, an ultrafast delivery pioneer, leveraged Amazon Redshift to democratize their data on a large scale through their data mesh architecture.
- Amazon Redshift data sharing powered the data mesh architecture that enabled data democratization, shorter time-to-market, and cost-efficiencies.
- Redshift data sharing allowed business line teams to have their own data and analytics capabilities, along with refined 360-degree views of data generated from all over the organization without duplication or overstepping compute boundaries.
- Moreover, Amazon Redshift and data mesh allowed Getir to maintain a chargeback model for ensuring costs were spread fairly across different teams and enabled the seamless propagation of newly created tables.
- Getir's case study showcases the strategic uses of a data mesh architecture and Amazon Redshift, but more importantly provides tremendous insights into five key trends across all industries.
- Those trends are interconnected, purpose-built data stores; data democratization; real-time insights to drive greater value from data; resilient data services ensuring business continuity; and leveraging generative AI to extract even deeper insights from data more expeditiously.
- Furthermore, data mesh architecture can play a crucial role in enabling and facilitating Retrieval Augmented Generation (RAG), thereby helping organizations harness the full potential of their data assets.
- In conclusion, Getir implemented a data mesh architecture and Amazon Redshift data sharing to meet their evolving data requirements, which entailed dedicated data warehouses tailored to different business lines and needs, while maintaining robust data governance and secure data access.
- The use of data mesh architecture and Amazon Redshift data sharing has proven to eliminate costly and barrier-inducing data silos and empowers data-driven decision-making.
- For more information, contact AWS or connect with your AWS Technical Account Manager or Solutions Architect.
Read Full Article
2 Likes
Currentanalysis
280

Image Credit: Currentanalysis
Google Cloud Summit UK: Integrating AI Across Silicon, Platform, Cloud, and Applications
- Google Cloud Summit UK: Integrating AI Across Silicon, Platform, Cloud, and Applications
- Google Cloud held its first annual summit in London, announcing expanded data residency in the UK for handling sensitive data.
- Google emphasized its vertically integrated AI strategy, from silicon chips to cloud, platform, models, and applications.
- Key announcements included on-premises offering Google Distributed Cloud and advancements in Agentic AI and business intelligence.
Read Full Article
16 Likes
Amazon
0

Image Credit: Amazon
Apache HBase online migration to Amazon EMR
- Apache HBase is a non-relational distributed database, which can host very large tables with billions of rows and millions of columns providing quick and random query function in e-commerce and high-frequency trading platforms.
- HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3).
- Amazon EMR 5.2.0, provides an option to run Apache HBase on Amazon S3. Running HBase on Amazon S3 provides benefits like lower costs, data durability, and easier scalability.
- For existing HBase clusters, we recommend using HBase snapshot and replication technologies to migrate to Apache HBase on Amazon EMR without significant downtime of service.
- HBase snapshots allow you to take a snapshot of a table without too much impact on region servers and exporting a snapshot to another cluster has little impact on the region servers. HBase replication is a way to copy data between HBase clusters.
- During HBase migration, you can export the snapshot files to S3 and use them for recovery.
- Customers can use BucketCache in file mode to enhance HBase’s read performance and thus cache data. The cache can be cleared by restarting the the region servers.
- It is recommended to choose a more recent minor version when migrating to Amazon EMR and keep the major version unchanged.
- Users sometimes face the issue of high response latency when accessing to HBase. It can be reduced by adding the host name and IP mapping to the /etc/hosts file in the HBase client host.
- This pieced provides the best practices for HBase online migration to Amazon EMR using HBase snapshot and replication and also covers the key challenges faced during migrations.
Read Full Article
Like
Cloudera
363

Image Credit: Cloudera
Cloudera and Snowflake Partner to Deliver the Most Comprehensive Open Data Lakehouse
- Cloudera and Snowflake have partnered to deliver the most comprehensive open data lakehouse.
- Cloudera added support for the REST catalog to prioritize open metadata for customers.
- Snowflake leverages Cloudera to build and manage Iceberg tables, providing a consistent view of data without data movement.
- The partnership offers advantages such as lower total cost of ownership, freedom to choose the best tools, and true hybrid access to data across multiple environments.
Read Full Article
21 Likes
Amazon
82

Image Credit: Amazon
Infor’s Amazon OpenSearch Service Modernization: 94% faster searches and 50% lower costs
- Infor has modernized its search capabilities using Amazon OpenSearch Service to improve its software products and offer a better service to customers.
- By modernizing their use of OpenSearch Service, Infor has been able to reduce storage costs by 50%, and deliver a 94% improvement in customer search performance.
- Infor’s ION OneView was built on top of Elasticsearch v5.x on Amazon OpenSearch Service, hosted across eight AWS Regions.
- In addition to updating OneView’s infrastructure, Infor rewrote long-running queries, improved indexing and memory and CPU utilization, and optimized instance selection for performance.
- The key benefits of modernizing Infor's ION OneView have included improved performance, reduced storage costs, and greater resilience.
- By partnering with Amazon Web Services, Infor was able to reduce operational burdens and take advantage of the latest features, such as Graviton support, bug fixes, and security posture improvements.
- The success of Infor's OpenSearch Service transformation demonstrates the importance of collaboration, technical expertise, and deploying best practices to meet unique workload demands.
- Allan Pienaar, an OpenSearch SME, and Gokul Sarangaraju, a Senior Solutions Architect at AWS, collaborated with Arjan Hammink, a Senior Director of Software Development at Infor, to optimize Infor’s search capabilities.
- Infor’s OpenSearch Service modernization empowers the company to provide an improved, high-performing search experience for their customers at a significantly lower cost.
- The improvements drive Infor’s ION OneView and help process even greater data volumes.
Read Full Article
4 Likes
TechBullion
400

Image Credit: TechBullion
Anurag Basani: An Engineer’s Insights On The Key Considerations for Modernizing an On-Premise Data Warehouse
- Organizations need to consider strategic decisions for cost, security, data governance and selecting the right cloud provider to modernize on-premise data warehouses with cloud computing.
- Businesses relied on on-premise data warehouses that struggle to scale as data needs grow, resulting in limited flexibility, high operational costs, and capacity constraints.
- On the other hand, cloud data warehouses offer elastic resources, the ability to scale on-demand, and pay-as-you-go models. Cloud-based infrastructure transformation is a strategic imperative for data-driven decision-making, says Anurag Basani, Senior Data Engineer at Meta.
- Migrating to the cloud offers the potential for cost savings. However, organizations must consider ongoing expenses such as data storage, compute resources, data transfer fees, and potential costs associated with data integration and governance.
- Shared responsibility models can ensure provider compliance with industry regulations, but organizations must correctly align cloud specialists, IT, and compliance teams, especially with data residency and sovereignty concerns.
- Organizations should consider potential data transfer bottlenecks, system latency, and scalability issues when migrating to the cloud. Running performance tests can help identify potential bottlenecks.
- Each cloud provider offers a range of services tailored to meet specific organization requirements, and businesses need to select the right cloud provider based on service offerings, data residency options, security protocols, and support for long-term growth.
- Assess provider roadmaps and capabilities in advanced technologies such as AI, machine learning, and data analytics to ensure alignment with long-term business strategy.
- Modernizing your data warehouse positions your business to thrive in a data-driven future.
Read Full Article
24 Likes
TechBullion
197

Image Credit: TechBullion
datma launches datma.FED: Pioneering a New Era in Healthcare Data Sharing and Monetization
- datma, a frontrunner in federated Real-World Data (RWD) platforms, announced the launch of datma.FED, a revolutionary marketplace poised to transform the healthcare data landscape.
- this two-sided marketplace is designed to address a persistent challenge in the healthcare industry: the secure, efficient, and profitable exchange of healthcare data between health systems, labs (data custodians), and pharmaceutical companies or research organizations (data consumers).
- Healthcare data is widely regarded as one of the most valuable resources for advancing medical research, improving patient outcomes, and driving pharmaceutical innovation.
- With datma.FED, datma is delivering an innovative federated model that redefines how healthcare data is accessed, monetized, and applied, providing a sustainable and secure data-sharing ecosystem.
- At the heart of datma.FED is its federated data access model, a revolutionary approach that addresses the core issues of privacy, security, and control.
- For data custodians, datma.FED opens up new opportunities for monetization without compromising privacy or control.
- The launch of datma.FED comes at a time when the global demand for real-world data is surging.
- Pharmaceutical companies, in particular, are increasingly turning to real-world data to supplement traditional clinical trial results and gain insights into patient outcomes, drug safety, and efficacy in real-world settings.
- By providing a secure, federated marketplace that connects data custodians and data consumers, the platform addresses the key challenges of privacy, control, and data access while enabling both sides to benefit from the growing demand for real-world data.
- The launch of datma.FED represents a significant milestone in the evolution of healthcare data sharing.
Read Full Article
11 Likes
Cloudera
211

The Evolution of LLMOps: Adapting MLOps for GenAI
- Machine learning operations (MLOps) have become the standard practice for developing, deploying, and managing machine learning models. With the rise of large language models (LLMs), we now need Large Language Model Operations (LLMOps) to address the unique challenges they pose.
- LLMOps introduces new processes and workflows compared to traditional MLOps such as expanding the builder persona, low-code/no-code as a core feature, focus on model optimization, prompt engineering, and retrieval-augmented generation (RAG).
- LLMOps focuses on prompt engineering, model optimization, and RAG. It also introduces new complexities in governance, risk management, and evaluation, making LLMOps crucial for successfully scaling and managing these advanced models in production.
- Data scientists are no longer the only ones involved in building LLMs. Business teams, product managers, and engineers play a more active role because LLMs lower the barrier to entry for AI-driven applications.
- Low-code/no-code tooling has become essential to cater to a broader set of users and make LLMs accessible across various teams.
- Model optimization techniques such as quantization, pruning, and prompt engineering are critical to refining LLMs to suit targeted use cases.
- Prompt engineering is the practice of crafting precise instructions to guide the model’s behavior, serving as a key method for improving the quality, relevance, and efficiency of LLM responses.
- Rise of Retrieval-Augmented Generation (RAG) architectures that integrate retrieval models to pull information from enterprise knowledge bases, and then rank and summarize that information using LLMs.
- Evaluating and monitoring LLMs is more complex than with traditional ML models. Enterprises are beginning to adopt AI risk frameworks, but best practices are still evolving.
- LLMOps is a crucial requirement for successfully scaling and managing advanced LLM models in production by focusing on governance, risk management, evaluation, and prompt engineering, to name a few.
Read Full Article
12 Likes
For uninterrupted reading, download the app