A naukri.com initiative
Databases
Hackernoon
72
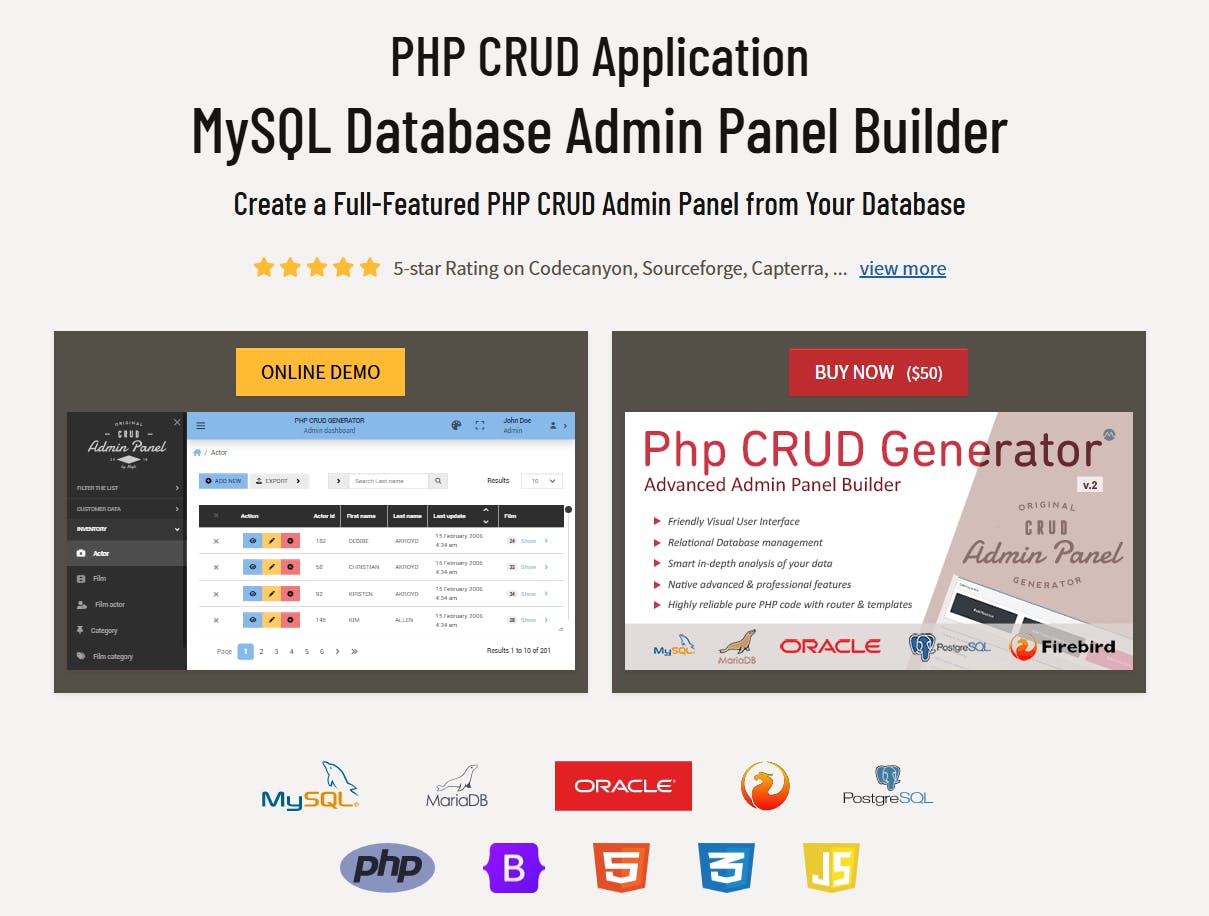
Image Credit: Hackernoon
PHP CRUD Generator – Instantly Build Admin Panels from Your Database
- PHP CRUD Generator is a tool developed to automate the process of creating admin panels and CRUD interfaces for MySQL databases.
- The generator analyzes tables, columns, and relationships in a MySQL database to produce a PHP admin panel with Bootstrap UI, authentication, role-based permissions, search, filtering, and data export/import.
- The generated code is clean, extensible, and customizable in terms of field types, validation, and user roles through the interface or code editing.
- Most customers of PHP CRUD Generator are developers or agencies looking to quickly deliver internal tools, dashboards, or client portals without the repetitive CRUD work involved.
Read Full Article
4 Likes
Dbi-Services
412
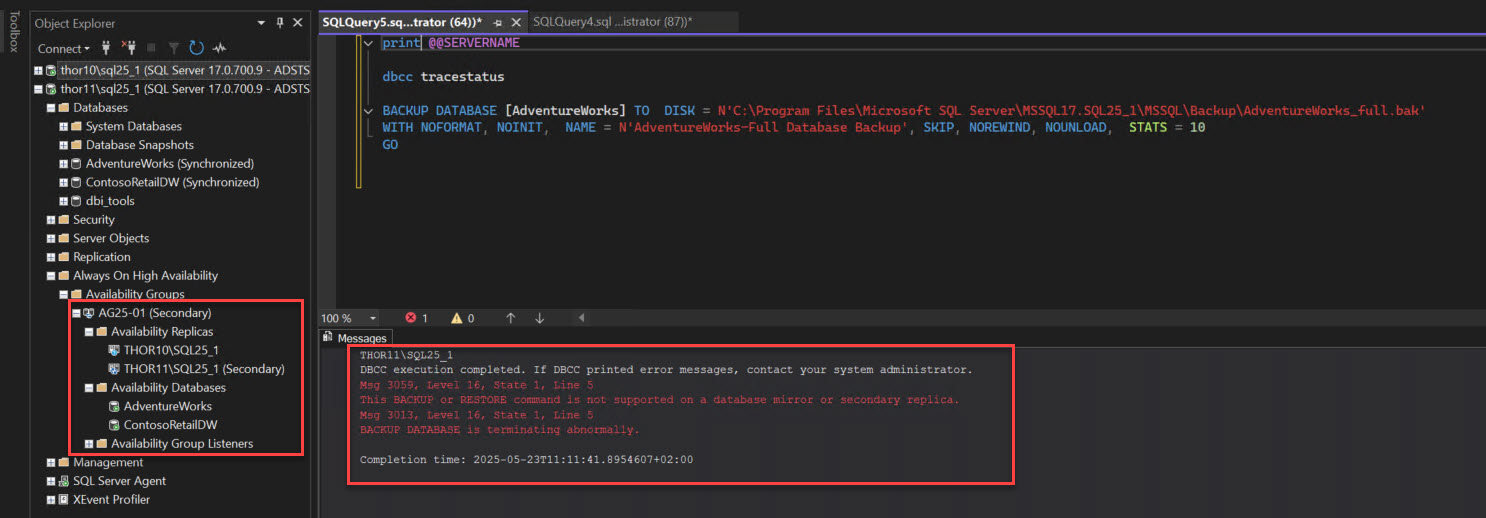
Image Credit: Dbi-Services
SQL Server 2025 – Backups to secondary replicas of an availability group
- SQL Server 2025 introduces the ability to perform normal Full backups and Differential backups on secondary replicas of an availability group.
- Before SQL Server 2025, limitations existed in performing Full and Differential backups on secondary replicas.
- New trace flags 3261 and 3262 need to be enabled to perform these new backups on secondary replicas.
- This enhancement allows for offloading backup workload from the primary replica to the secondary, providing more robust backup configurations.
Read Full Article
24 Likes
Dbi-Services
172

Image Credit: Dbi-Services
Ansible: reduce output in loops – or replace loops
- When using loops in Ansible, the output can become cluttered, especially when working with lists of dictionaries.
- Using the no_log: true option helps reduce output clutter by replacing the item-values with 'None,' but it may hinder error troubleshooting.
- An alternative method is to loop over index numbers of list elements instead of the list directly.
- This indexing approach makes output more compact and easier to read.
- For large datasets, it is recommended to use json_query for filtering data efficiently instead of traditional looping.
- When retrieving data from LDAP or web services, fetching all data at once and then extracting host-specific information using json_query is more efficient than querying individually for each host.
- Using json_query can help streamline data extraction and enhance playbook performance in scenarios involving multiple hosts.
- In summary, to reduce output clutter in loops, consider options like no_log: true, indexing list elements, and leveraging json_query for data filtering in Ansible.
Read Full Article
10 Likes
Analyticsindiamag
453

Image Credit: Analyticsindiamag
OpenAI, G42, Oracle, NVIDIA and Others Launch Stargate UAE for AI Infrastructure
- Global technology firms, including G42, OpenAI, Oracle, NVIDIA, SoftBank Group, and Cisco, have launched Stargate UAE, a 1-gigawatt AI compute cluster in Abu Dhabi.
- Stargate UAE is part of the 'US–UAE AI Acceleration Partnership' to enhance collaboration on artificial intelligence and digital infrastructure between the two countries.
- The initiative involves G42 developing Stargate UAE, which will be operated jointly by OpenAI and Oracle, while Cisco and NVIDIA will provide infrastructure and systems.
- The UAE–U.S. AI Campus, hosting Stargate UAE, aims to provide 5 gigawatts of data centre capacity across 10 square miles, powered by a mix of nuclear, solar, and natural gas energy.
Read Full Article
22 Likes
Discover more
- Programming News
- Software News
- Web Design
- Devops News
- Open Source News
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Dbi-Services
36
Image Credit: Dbi-Services
SQL Server 2025 – ZSTD – A new compression algorithm for backups
- SQL Server 2025 introduces a new compression algorithm for backups called ZSTD, alongside existing solutions MS_XPRESS and QAT.
- Tests were conducted using a virtual machine with Windows Server 2022 Datacenter and SQL Server 2025 Standard Developer for comparing MS_XPRESS and ZSTD.
- ZSTD can be implemented in SQL backup commands or changed at the instance level to enhance backup performance and reduce CPU load.
- Comparative analysis revealed that ZSTD offers faster backup creation, lower CPU load due to quicker backups, and reduced backup size, indicating its potential benefits.
Read Full Article
2 Likes
Amazon
63

Image Credit: Amazon
Amazon Aurora Global Database introduces support for up to 10 secondary Regions
- Amazon Aurora Global Database now supports up to 10 secondary Regions, enhancing scalability and resilience for globally distributed applications.
- This feature allows a single Aurora database to span multiple AWS Regions, replicating data asynchronously with minimal impact on performance.
- Aurora Global Database enables fast local reads with low latency in each Region and offers disaster recovery in case of Regional impairment.
- The update supports both Amazon Aurora MySQL-Compatible Edition and Amazon Aurora PostgreSQL-Compatible Edition versions in global configurations.
- Aurora Global Database consists of one primary Region and up to 10 read-only secondary Regions for low-latency local reads.
- Global Database switchover and failover capabilities allow for changing the primary cluster location in a global cluster.
- The increased secondary Region support of up to 10 enhances scalability for applications with a global presence and multiple offices worldwide.
- Aurora Global Database's support for a 'Follow the Sun' model is beneficial for minimizing latencies in globally available applications.
- Extending deployment to include up to 10 secondary Regions in Aurora Global Database is seamless and can be managed through various interfaces.
- Overall, the expansion to 10 secondary Regions offers significant flexibility, scalability, and resilience for diverse application needs.
Read Full Article
3 Likes
Silicon
99

Image Credit: Silicon
UAE ‘Stargate’ Data Centre To Begin Operation In 2026
- The first phase of the UAE's largest data centre complex, Stargate UAE, will begin operations in 2026 under the 'Global Tech Alliance', a partnership that aims to build a next-generation AI infrastructure cluster.
- The Stargate UAE project was part of a deal brokered by US President Donald Trump during his visit to the region, despite previous restrictions on sending advanced technology to the UAE due to its ties with China.
- The UAE and the US reached a preliminary deal to allow the UAE to import 500,000 advanced Nvidia AI chips annually starting in 2025, with a significant portion allocated to UAE firms like G42.
- The Stargate UAE will be a 1-gigawatt compute cluster operated by OpenAI and Oracle, expected to go live in 2026, and aims to transform the UAE into a major provider of AI data centers in the region.
Read Full Article
6 Likes
Dev
1.2k

Image Credit: Dev
Statistics by Time Window — From SQL to SPL #31
- Task: Divide the data into one-minute windows, fill in missing windows, and calculate start_value, end_value, min, and max for each window.
- SQL code requires complex nested subqueries and join statements, making it lengthy and hard to understand.
- SPL (Structured Pattern Language) provides time series functions and sequence-aligned functions, making it easier to implement tasks like window division.
- SPL steps involve loading data, adjusting time to full minutes, creating a continuous minute time series list, aligning data with the list, and generating a new table with calculated values for each window.
Read Full Article
7 Likes
Dev
417

Image Credit: Dev
SQL COALESCE Explained: Simplify NULL Handling in Queries
- SQL COALESCE function is a valuable tool for managing NULL values in SQL queries efficiently.
- It returns the first non-NULL value from a list of expressions and can be used to provide fallback values.
- COALESCE helps in handling missing data, providing default values, and simplifying logic in SQL queries.
- By mastering COALESCE, SQL developers can improve data clarity, maintainability of code, and overall query performance.
Read Full Article
25 Likes
Amazon
390

Image Credit: Amazon
How to configure a Linked Server between Amazon RDS for SQL Server and Teradata database
- Amazon RDS for SQL Server can now use Teradata databases as external data sources via linked server configuration, allowing command execution and data reading from remote servers.
- This setup allows connections between Amazon RDS for SQL Server and a Teradata database, whether on AWS or on-premises, using ODBC connectivity.
- Linked servers with Teradata ODBC are supported for specific versions of SQL Server and Teradata Database.
- To activate ODBC_TERADATA on an RDS instance, you can create or use an existing option group based on your RDS DB instance edition.
- The linked server setup involves creating an option group, associating it with your DB instance, and configuring the linked server for Teradata.
- Connection details like server name, Teradata DB instance, login credentials, encryption, SSL mode, and database name are required for setting up the linked server.
- By using stored procedures like sp_addlinkedserver, a linked server between RDS instances running SQL Server and Teradata can be created.
- You can verify the connectivity to the remote data source using queries through the linked server.
- To clean up resources, you can remove linked servers using sp_dropserver, delete RDS instances, and delete associated option groups.
- Configuring a linked server facilitates distributed queries, cross-database reporting, and secure connections between Amazon RDS for SQL Server and Teradata database for effective data integration.
Read Full Article
23 Likes
Cloudblog
186

Image Credit: Cloudblog
A deep dive into AlloyDB’s vector search enhancements
- AlloyDB for PostgreSQL offers vector search capabilities for structured and unstructured data queries, essential for generative AI applications and AI agents.
- AlloyDB AI’s ScaNN index enhancements at Google Cloud Next 2025 aim to boost search quality and performance across both structured and unstructured data.
- Filtered vector search in AlloyDB enables efficient search across metadata, texts, and images in scenarios like managing a vast product catalog for an online retailer.
- AlloyDB's query planner optimizes filter selectivity to determine the order of SQL filters in vector search, improving search speed and precision.
- Highly selective filters, like rare colors in a product catalog, are usually applied as pre-filters to reduce the candidate pool for vector search.
- Low-selectivity filters, such as common product attributes, are more efficiently applied as post-filters after an initial vector search to avoid excessive candidates.
- For medium-selectivity filters, AlloyDB supports in-filtering, applying filter conditions alongside vector search to strike a balance between pre-filtering and post-filtering.
- AlloyDB's adaptive filtration feature allows dynamic adjustment of filter order based on observed statistics, enhancing search result quality and performance.
- By smartly managing filter selectivity and integrating efficient vector search, AlloyDB ensures high-quality search results as data and workloads evolve.
- AlloyDB's ScaNN-powered vector search with adaptive filtration is recommended for real-world applications, offering advanced search capabilities across structured and unstructured data.
- Start leveraging AlloyDB’s ScaNN index for vector search and explore the adaptive filtration feature to enhance the quality and performance of your search queries today.
Read Full Article
11 Likes
Javarevisited
154
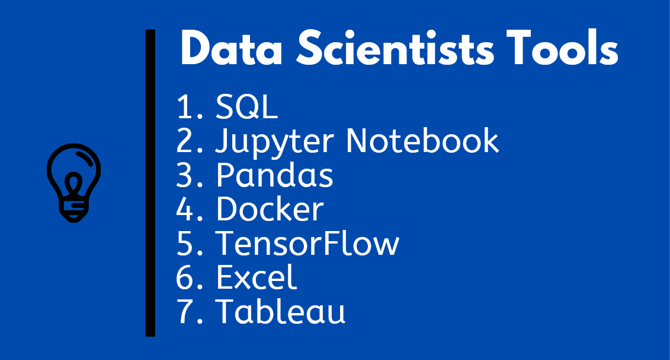
Image Credit: Javarevisited
Top 10 Tools Data Scientists and Machine Learning Developer Should Learn in 2025
- Tools and libraries play a crucial role in enhancing the efficiency of Data Scientists and Machine Learning developers.
- Data Science and Machine Learning require powerful tools for tasks such as data normalization, cleaning, visualization, and model building.
- In 2025, essential tools for Data Scientists and Machine Learning developers are being highlighted as crucial for dealing with large datasets effectively.
- Previous essential tools recommendations for Software developers, Java developers, Python developers, and Web Developers have been shared, emphasizing the importance of having the right tools in various fields.
Read Full Article
9 Likes
Dev
322

Image Credit: Dev
What is SQL and Why You Should Learn It
- SQL (Structured Query Language) is the standard language for interacting with relational databases, allowing users to manage data efficiently.
- Common use cases of SQL include data retrieval, database management, reporting & analytics, data cleaning, and integrations.
- Learning SQL is beneficial as it is beginner-friendly, works across various database systems, and is in high demand in tech jobs.
- SQL is essential for web developers, data scientists, and anyone working with structured data, providing powerful querying capabilities and vast opportunities for skill development.
Read Full Article
19 Likes
Amazon
386

Image Credit: Amazon
Achieve up to 1.7 times higher write throughput and 1.38 times better price performance with Amazon Aurora PostgreSQL on AWS Graviton4-based R8g instances
- Upgrading to Graviton4-based R8g instances with Aurora PostgreSQL-Compatible 17.4 on Aurora I/O-Optimized cluster configuration offers up to 1.7 times higher write throughput, 1.38 times better price-performance, and reduced commit latency.
- Amazon Aurora PostgreSQL-Compatible now supports AWS Graviton4-based R8g instances and PostgreSQL major version 17.4, leading to key performance improvements for Amazon Aurora I/O-Optimized configurations.
- Graviton4-based R8g instances provide improved performance, scalability, and better price-performance for memory-intensive workloads, featuring up to 192 vCPUs and 1.5 TB of memory.
- PostgreSQL 17 introduces vacuum improvements, SQL/JSON standards expansion, enhanced query performance, and greater partition management flexibility.
- Aurora PostgreSQL-Compatible enables independent scaling through a distributed storage architecture, reducing I/O operations and improving performance.
- Performance improvements on Graviton4-based R8g instances with Aurora PostgreSQL-Compatible 17.4 enhance write throughput and commit latency across various applications.
- The Aurora I/O-Optimized cluster configuration optimizes write operations, introduces smart batching, and separates critical write paths for improved performance.
- Benchmarking using HammerDB shows significant performance gains with Graviton4-based R8g instances and Aurora PostgreSQL version 17.4.
- Upgrading to Graviton4-based R8g instances from Graviton2 and PostgreSQL 15.10 to 17.4 demonstrates substantial performance improvements.
- The combined hardware and database engine version upgrade offer the most significant performance benefits with improved price performance and ratio for various workload sizes.
- The Aurora PostgreSQL-Compatible 17.4 and Graviton4-based R8g instances deliver consistent performance enhancements, enabling organizations to provide more responsive services.
Read Full Article
23 Likes
Dev
317

Image Credit: Dev
IoT monitoring with Kafka and Tinybird
- Combining Apache Kafka-compatible streaming service with Tinybird can create real-time data APIs for IoT devices.
- Kafka excels at high-throughput event streaming, while Tinybird transforms data into real-time APIs with sub-second response times.
- Utility companies utilize smart meters for real-time readings, and the Kafka + Tinybird stack provides real-time insights and APIs for customer-facing features.
- Setting up Kafka connection to Tinybird involves creating connections and data sources, simplifying the data ingestion process.
- Tinybird Local allows testing analytics backend locally before deploying to a cloud production environment.
- Creating API endpoints with Tinybird involves generating resources like endpoint configurations that accept parameters and return values.
- Deployment to cloud production environment involves setting up secrets, proper testing, and monitoring of sensors.
- Automated testing with Tinybird ensures project stability and avoids potential future issues.
- The architecture simplifies IoT data processing by using Kafka for streaming and Tinybird for creating real-time APIs.
- The system allows for scalability, version control, and easy maintenance of data processing pipelines.
Read Full Article
19 Likes
For uninterrupted reading, download the app