A naukri.com initiative
Databases
Hackernoon
117

Image Credit: Hackernoon
Navigating MySQL Numeric Data Types
- MySQL provides various numeric data types including integer, fixed-point, floating-point, and bit types for storing numeric values efficiently.
- Integer types in MySQL support signed and unsigned values, with options like ZEROFILL being deprecated.
- Fixed-point types like DECIMAL are suitable for exact numeric values such as currency, while floating-point types like DOUBLE are ideal for approximate values.
- Tips include choosing the smallest integer that fits, utilizing UNSIGNED for non-negative values, and using DECIMAL for monetary values to ensure data integrity and avoid common pitfalls.
Read Full Article
7 Likes
Amazon
239

Image Credit: Amazon
Automate Amazon RDS for PostgreSQL major or minor version upgrade using AWS Systems Manager and Amazon EC2
- Automating Amazon RDS for PostgreSQL major or minor version upgrades using AWS Systems Manager and Amazon EC2 simplifies database lifecycle management.
- Manual upgrades through AWS Management Console can be error-prone and disrupt application stability.
- The automation process involves AWS CLI commands in a Unix shell script and integration with AWS Systems Manager for scaling.
- Pre-upgrade checks and instance maintenance updates are executed through reusable modules: PREUPGRADE and UPGRADE.
- Logging and notification features are added for monitoring and notification through Amazon S3 and Amazon SNS.
- The solution supports major and minor version upgrades and can be extended for multi-VPC or cross-account deployments with additional considerations.
- Prerequisites include IAM user permissions, cloning the GitHub repository, preparing RDS instances, creating S3 bucket, SNS topic, IAM policy, and IAM role.
- An EC2 instance hosts and runs the upgrade script requiring AWS CLI, PostgreSQL client, bc, and jq library.
- Implementation steps include uploading the script to S3, creating an Automation Document, and executing the upgrade process through Systems Manager.
- Comprehensive monitoring and notification mechanisms are in place, providing logs for pre-upgrade and upgrade phases.
Read Full Article
14 Likes
Amazon
185

Image Credit: Amazon
Supercharging vector search performance and relevance with pgvector 0.8.0 on Amazon Aurora PostgreSQL
- Amazon Aurora PostgreSQL-Compatible Edition now supports pgvector 0.8.0, enhancing vector search capabilities for applications requiring semantic search and Retrieval Augmented Generation (RAG).
- pgvector 0.8.0 on Aurora PostgreSQL-Compatible delivers up to 9x faster query processing and 100x more relevant search results, addressing scaling challenges for enterprise AI applications.
- Improvements in pgvector 0.8.0 include enhanced performance, complete result sets, efficient query planning, and flexible performance tuning for vector search applications.
- Overfiltering issues in previous versions of pgvector are addressed by iterative index scans in pgvector 0.8.0, providing improved query reliability and performance in filtered vector searches.
- Query examples demonstrate the impact of pgvector 0.8.0 improvements, showcasing better performance, result completeness, and cost estimation accuracy in complex filtering scenarios.
- Benchmark tests highlight significant performance enhancements with pgvector 0.8.0 compared to 0.7.4, showing faster query processing and improved result quality across various query patterns.
- Best practices for utilizing pgvector 0.8.0 on Aurora PostgreSQL-Compatible include optimizing index configurations, query-time tuning, and operational considerations for efficient vector search implementations.
- pgvector 0.8.0 boosts semantic search, recommendation systems, and RAG applications by offering faster retrieval, lower latency, improved recall, and complete result sets for large-scale AI applications.
- Aurora PostgreSQL-Compatible's scalability combined with pgvector 0.8.0's enhancements provides a robust foundation for enterprises to build high-performance AI applications.
- Integration of pgvector 0.8.0 into applications is supported by Amazon Aurora resources and operational best practices to optimize vector storage, retrieval, and query performance.
- pgvector 0.8.0 on Aurora PostgreSQL-Compatible empowers organizations with advanced vector search capabilities, ensuring responsive, accurate, and cost-effective AI applications as data scales.
Read Full Article
11 Likes
Sdtimes
352
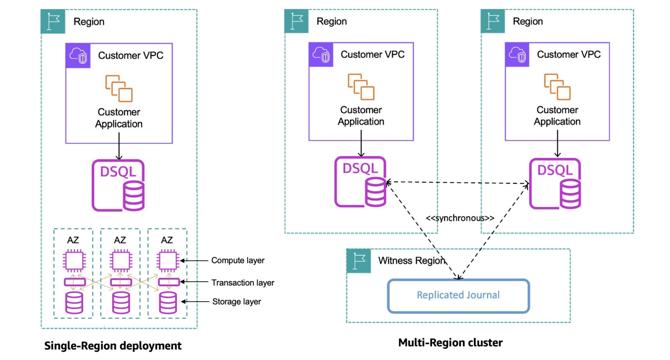
Image Credit: Sdtimes
Amazon launches serverless distributed SQL database, Aurora DSQL
- Amazon has announced the general availability of Amazon Aurora DSQL, a serverless distributed SQL database focused on scalability, high availability, and zero infrastructure management.
- Aurora DSQL ensures 99.99% availability in a single region and 99.999% availability across multiple regions through features like replicating committed log data to user storage replicas across three Availability Zones.
- Multi-region clusters in Aurora DSQL improve availability by utilizing Regional endpoints for read and write operations, with a third Region acting as a log-only witness for optimal geographic location optimization.
- Aurora DSQL is suited for applications using microservices and event-driven architectures, with added features like an MCP server for natural language interaction and improvements in cluster management, AWS service integration, and PostgreSQL support.
Read Full Article
21 Likes
Discover more
- Programming News
- Software News
- Web Design
- Devops News
- Open Source News
- Cloud News
- Product Management News
- Operating Systems News
- Agile Methodology News
- Computer Engineering
- Startup News
- Cryptocurrency News
- Technology News
- Blockchain News
- Data Science News
- AR News
- Apple News
- Cyber Security News
- Leadership News
- Gaming News
- Automobiles News
Medium
27
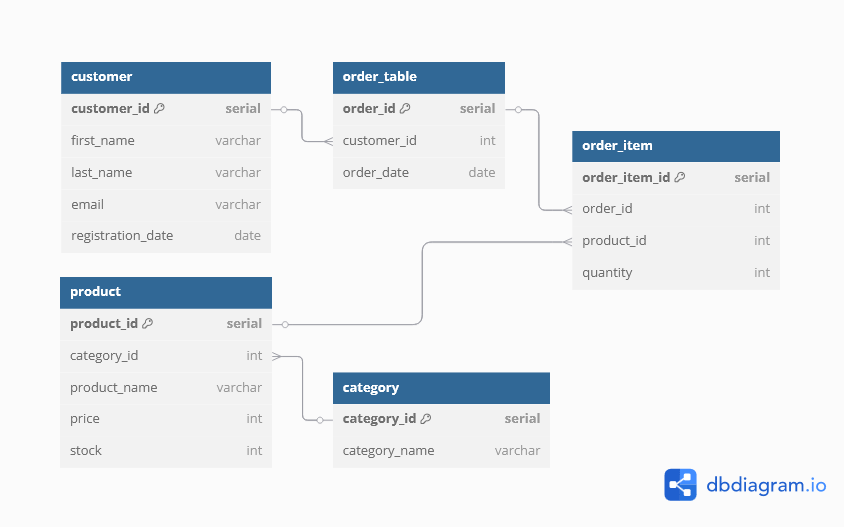
Image Credit: Medium
Mini Project with PostgreSQL: Customer & Order Management
- This mini project involves creating a 'Product' table in PostgreSQL for customer and order management.
- Data is being populated to simulate real-world e-commerce operations, emphasizing the importance of meaningful sample data.
- Various queries are demonstrated, including filtering products based on price, retrieving electronic product names and prices, and calculating total order value per customer.
- Over 20 meaningful queries are provided in the 'queries.sql' file to extract business insights like total order value, popular products, and customer activity.
Read Full Article
1 Like
Medium
108

Image Credit: Medium
How to Crack Any SQL Interview for Data Engineering in 2025?
- SQL interviews for Data Engineering in 2025 typically involve assessing candidates' ability to write efficient and effective SQL queries.
- Candidates are evaluated on their SQL problem-solving skills, understanding of filtering, aggregation, joins, CTEs, and window functions.
- Foundational SQL patterns such as filtering data, grouping, and aggregating before further filtering are crucial for aspiring data engineers.
- Understanding different types of joins and when to use each, like INNER JOIN, LEFT JOIN, and ANTI-JOIN, is essential in SQL interviews.
- Performance tuning and knowledge of table scans, indexing, and partitioning are key aspects tested in SQL interviews for data engineering roles.
- Candidates are expected to demonstrate proficiency in using window functions, Common Table Expressions (CTEs), and self-joins in SQL queries.
- Efficient SQL writing, clarity in logic, and understanding query performance are crucial skills looked for in SQL interviews.
- Candidates are advised to optimize queries, avoid redundant scans, and think like a production-ready data engineer during SQL assessments.
- Thinking beyond correctness to consider efficiency, readability, and scalability is key to excelling in SQL interviews for data engineering roles.
- Real-world scenario-based SQL tasks are often used to evaluate candidates' problem-solving abilities and SQL proficiency.
- The ability to write modular, efficient SQL queries that demonstrate clear thinking and scalability is a distinguishing factor in data engineering interviews.
Read Full Article
6 Likes
Siliconangle
217

Image Credit: Siliconangle
Cast AI debuts Database Optimizer to streamline cloud database caching
- Cast AI Group Inc. has launched Database Optimizer, a new approach to caching that enhances cloud database performance by providing a fully autonomous caching layer that requires zero application changes or manual tuning.
- Database Optimizer simplifies operations and reduces wasteful database spending, making it easier for DevOps personnel, platform engineers, and cloud database administrators to manage.
- Key features of Database Optimizer include simplified optimization, immediate performance improvements, up to 10 times faster data retrieval, and automation that helps cut operational costs while maintaining high performance.
- Early users like Akamai Technologies Inc. and Flowcore Technologies Inc. have praised the DBO offering, with significant improvements in performance and cost reduction. Cast AI recently raised $108 million in new funding to enhance its platform.
Read Full Article
13 Likes
Dev
289

Image Credit: Dev
Is This a Refreshing Way to Understand Association?
- Association in SQL involves Cartesian product and filtering, similar to Python.
- EsProc SPL defines association differently, involving foreign key and primary key association.
- SPL's foreign key association is about associating regular fields with primary keys of another table.
- SPL treats foreign keys as objects, enabling direct access to related table fields.
- Primary key association in SPL involves matching record objects, making it more intuitive.
- SPL offers a more natural and error-resistant approach compared to SQL and Python.
- SQL requires explicit specification and recalculations for each association.
- Python's association results can be cumbersome due to wide tables.
- SPL's approach to association is more flexible and suitable for complex computations.
- SQL and Python are prone to errors in many-to-many association scenarios, unlike SPL.
Read Full Article
17 Likes
Dbi-Services
303
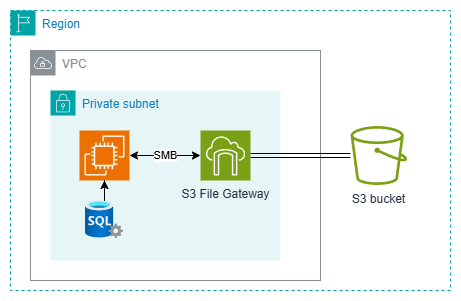
Image Credit: Dbi-Services
Random permission denied when backing up SQL Server databases to AWS Storage Gateway
- When hosting SQL Server on AWS EC2 instances, a backup strategy is crucial.
- AWS S3 is a reliable option for persisting and archiving backups securely.
- Using AWS Storage Gateway with File Gateway as an intermediary service is necessary for backing up to S3.
- To address the 'Access is denied' error during backups, enabling Trace Flag 3042 can be a workaround.
Read Full Article
18 Likes
Gizchina
273

Image Credit: Gizchina
Oracle to Spend $40 Billion on Nvidia Chips for AI Expansion
- Oracle is purchasing Nvidia chips worth $40 billion to establish a massive AI-focused data center in Texas as part of its global Stargate Project.
- The Texas facility will span 875 acres, consist of eight buildings, and use 1.2 gigawatts of electricity. It will house around 400,000 Nvidia GB200 superchips.
- In addition to Nvidia's chips, the Stargate Project is receiving significant funding from Crusoe Energy Systems, Blue Owl Capital, and JPMorgan. Oracle plans to build AI campuses worldwide, including in the UAE.
- This strategic move by Oracle signals a substantial investment in AI, positioning the company competitively in the AI landscape and highlighting the industry's focus on AI advancement.
Read Full Article
15 Likes
Infoq
357

Image Credit: Infoq
Java at 30: A Retrospective on a Language That Has Made a Big Impact
- Java programming language was introduced by Sun Microsystems at the Sun World conference in 1995, characterized as simple, object-oriented, distributed, and high-performance.
- Java, originally named Oak, was created to be architecture agnostic and object-oriented for consumer applications.
- Java has evolved over the past 30 years, overcoming challenges like being considered 'slow' or 'dead', with Oracle's recent initiatives focusing on making the language more accessible to students.
- To celebrate Java's 30th birthday, Oracle hosted a special event featuring discussions on language stewardship, community outreach, education, and the future of Java, highlighting its continued importance.
Read Full Article
21 Likes
Infoq
209
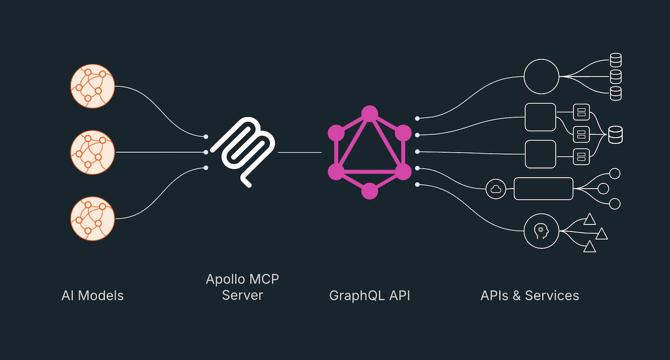
Image Credit: Infoq
Apollo GraphQL Launches MCP Server: A New Gateway Between AI Agents and Enterprise APIs
- Apollo GraphQL introduced the MCP Server to facilitate the integration of AI agents with existing APIs using GraphQL, enabling faster time-to-value and reducing development overhead.
- The Model Context Protocol (MCP) serves as a standardized interface between large language models and enterprise systems, enhancing connectivity and enabling various AI tasks.
- Utilizing GraphQL, the Apollo GraphQL MCP Server creates a scalable layer connecting AI agents with backend APIs for tasks like querying data and executing business logic.
- The integration of GraphQL with MCP allows for deterministic execution, selective data retrieval, and embedded policy enforcement, crucial for AI systems interacting with multiple APIs.
- MCP offers tools for interfacing with REST APIs via Apollo Connectors, facilitating the adoption of AI interfaces with minimal disruption to existing services.
- Major industry players such as HashiCorp, GitHub, and Docker have started offering MCP-compatible solutions, signaling the importance of tool-aware AI in the development landscape.
- The declarative approach of Apollo GraphQL's MCP tools aids in governance by abstracting APIs and services, ensuring data security and policy adherence across different systems.
- GraphQL and MCP serve as a solution to anti-patterns in AI-API orchestration, ensuring deterministic execution, efficient token usage, policy enforcement, and adaptable implementations.
- The Apollo MCP Server offers query plan visibility for tracing AI-generated queries and orchestrated API flows, enhancing observability and debugging capabilities.
- Apollo Federation plays a vital role in multi-domain MCP deployments, allowing AI to reason across separate team domains by presenting a unified semantic layer for seamless traversal.
Read Full Article
12 Likes
Soais
4

UiPath Agent Builder: A Simple Overview
- UiPath Agent Builder is a tool for creating AI agents—virtual assistants that can understand natural language and interact with UiPath workflows.
- Agent Builder introduces flexible, decision-making logic using AI while being grounded in data and controlled by guardrails.
- It is native to UiPath, low code, and offers governance features like escalation and audit logs for compliance and predictability.
- UiPath is evolving the platform with upcoming support for more AI models, additional templates, and better Langchain support.
Read Full Article
Like
Dev
203

Image Credit: Dev
Introduction to PostgreSQL
- PostgreSQL is an advanced open-source RDBMS supporting SQL and JSON querying, with origins dating back to 1986 at UC Berkeley.
- Key features include ACID compliance, MVCC, and extensibility, making it suitable for various workloads.
- Installation requirements for PostgreSQL include modest hardware specifications and platform-specific installation methods.
- Configuration involves editing files like postgresql.conf and using the psql command-line tool for database management and administration.
- PostgreSQL's architecture follows a client-server model, with key processes like WAL writer and background writer for data management.
- Core concepts cover databases, schemas, tables, data types, constraints, indexes, and views within PostgreSQL.
- SQL operations like CRUD, joins, subqueries, aggregations, and transactions are fundamental to working with PostgreSQL.
- Advanced features include window functions, CTEs, JSONB support, full-text search, and query optimization techniques.
- Security measures like roles, permissions, SSL encryption, and row-level security enhance data protection in PostgreSQL.
- Deployment best practices, scaling strategies, maintenance procedures, and the PostgreSQL ecosystem are crucial for production use.
Read Full Article
12 Likes
Dbi-Services
294
Optimize materialization of Exadata PDB sparse clones
- A company using Exadata sparse clones for database provisioning faced slow materialization times for sparse clones compared to full clones.
- The issue was identified as a result of Oracle sequentially performing online database move operations, slowing down the process.
- Monitoring the materialization process was possible through queries on GV$SESSION_LONGOPS.
- The company optimized the process using Python scripts with cx_Oracle driver, enabling parallel task execution and reducing the materialization time to that of creating a full PDB clone.
Read Full Article
17 Likes
For uninterrupted reading, download the app