A naukri.com initiative
Neural Networks News
Medium
132

Image Credit: Medium
How to use Checkpoint Strategies with Keras and TensorFlow: Ensuring Training Resilience
- Model checkpointing is a strategic process in deep learning workflows, designed to save snapshots of your model’s state at specified intervals.
- Both Keras and TensorFlow offer built-in mechanisms to automate the checkpointing process, with the ModelCheckpoint callback in Keras providing a flexible approach.
- Implementing model checkpointing involves preparing the dataset, defining the model, configuring the ModelCheckpoint callback, and initiating the training process.
- Early stopping is another powerful technique that can be used alongside model checkpointing to automatically stop training when a monitored metric stops improving.
Read Full Article
7 Likes
Medium
167
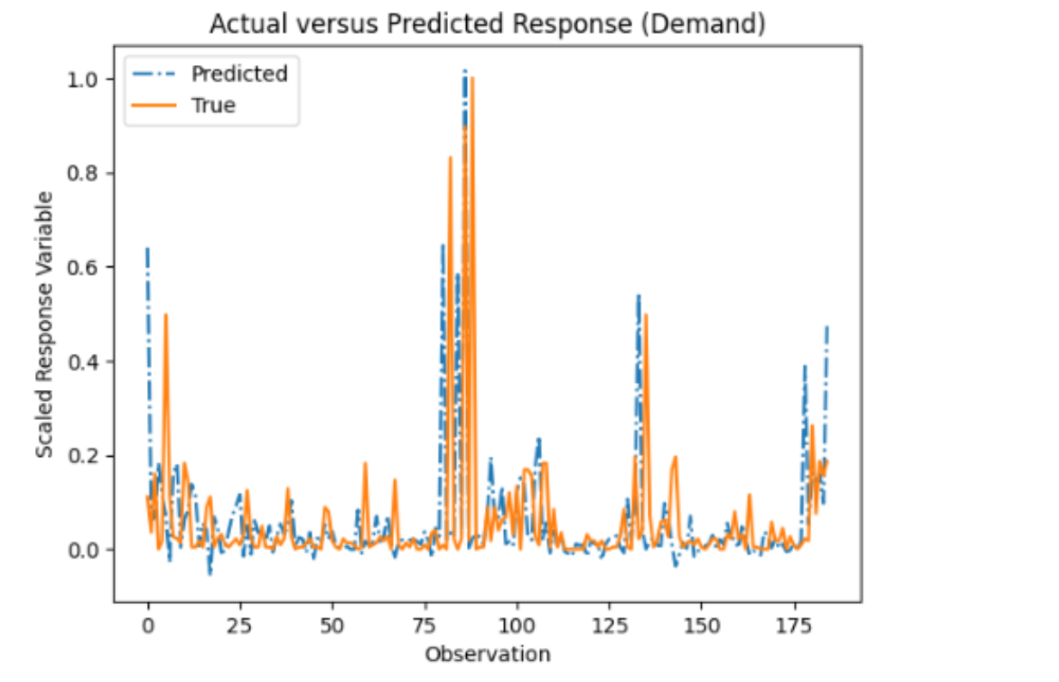
Image Credit: Medium
Enhancing Humanitarian Logistics with Advanced Demand Forecasting: A Deep Dive into Fuel Demand…
- Enhancing humanitarian logistics through advanced demand forecasting.
- Preparation of dataset by normalizing fuel consumption records.
- Utilization of Robust Principal Component Analysis (RPCA) for separating relevant patterns of fuel demand.
- Application of Long Short-Term Memory (LSTM) network for accurate predictions and evaluation of model's performance.
Read Full Article
10 Likes
Medium
231

Image Credit: Medium
Well Neural Link…….Elon’s brain chips actually work on humans
- A 29-year-old man was paralyzed from the shoulder down in a diving accident.
- He now has a mouse cursor under control and can do all sorts of things: play games like chess and Civ 6, surf the web, send text messages — all only by the thought.
- The chip itself is not installed by a human surgeon but a surgical robot.
Read Full Article
13 Likes
Hackernoon
417

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Experimental Results
- The experimental results highlight the tradeoff between memory frequency and maximum GPU frequency in energy consumption patterns for different models and devices.
- The optimization landscape can be significantly influenced by batch size, emphasizing the need for an adaptive framework.
- Figures 6-12 showcase the energy consumption patterns of EfficientNet and Bert on Jetson TX2 and Orin under various batch sizes.
- Table 7 presents the optimal CPU frequency and corresponding energy consumption reduction in image preprocessing.
Read Full Article
25 Likes
Hackernoon
18

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Opportunities
- Memory frequency tuning plays a vital role in reducing energy consumption in neural network inference.
- Throttling the CPU frequency can decrease preprocessing energy consumption by approximately 30%.
- Tuning the minimum GPU frequency can significantly reduce energy consumption when the workload cannot fully utilize the computational power of the hardware.
- Increasing the minimum GPU frequency leads to lower energy costs and inference latency.
Read Full Article
1 Like
Hackernoon
385

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Motivation
- Many deep neural networks have been deployed on edge devices to perform tasks such as image classification, object detection, and dialogue systems.
- Prior works have focused on optimizing the energy consumption of GPUs in cloud scenarios and training settings, but on-device inference workloads exhibit different characteristics and warrant separate attention.
- Prior work in optimizing on-device neural network inference focuses on quantization, designing hardware-friendly network architectures, and leveraging hardware components specific to mobile settings.
- Our work explores an orthogonal dimension and aims to answer a different question: Given a neural network to deploy on a specific device, how can we tune the device to reduce energy consumption?
Read Full Article
23 Likes
Hackernoon
267

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Arithmetic Intensity
- This paper discusses PolyThrottle, an energy-efficient neural network inference method for edge devices.
- The paper focuses on the concept of arithmetic intensity in neural network inference.
- It introduces a model that predicts inference latency based on computation power, memory bandwidth, and fixed overhead.
- The goal is to optimize energy efficiency in inference tasks on edge devices.
Read Full Article
16 Likes
Hackernoon
235

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Hardware Details
- The paper discusses the hardware details of the PolyThrottle energy-efficient neural network inference on edge devices.
- The Jetson TX2 Developer Kit features a 256-core NVIDIA Pascal GPU, a Dual-Core NVIDIA Denver 2 64-bit CPU, a Quad-Core ARM Cortex-A57 MPCore CPU, and 8GB of 128-bit LPDDR4 memory with 59.7 GB/s bandwidth.
- The Jetson Orin Developer Kit includes a 2,048-core NVIDIA Ampere GPU with 64 Tensor Cores and a 12-core Arm CPU. It comes with 32GB of 256-bit LPDDR5 memory with a bandwidth of 204.8GB/s and a maximum power consumption of 60W.
- Power consumption measurements are performed using the Jetson TX2 Developer Kit's power input and the Jetson Orin uses the built-in tegrastats module. The measurements are cross-validated using a USB digital multimeter.
Read Full Article
14 Likes
Hackernoon
272

Image Credit: Hackernoon
Modeling Workload Interference
- This paper proposes a performance modeling approach to predict inference latency in the presence of fine-tuning requests.
- The performance model selects features such as inference FLOPs, arithmetic intensity, fine-tuning FLOPs, fine-tuning arithmetic intensity, and batch size to capture resource contention.
- A linear model is used to predict the inference latency, and the non-negative least squares solver is employed to find the best-fitting model.
- The proposed approach is implemented in the Fine-tuning scheduler, which decides whether it is possible to schedule a fine-tuning request online without violating the service-level objective (SLO).
Read Full Article
16 Likes
Hackernoon
235

Image Credit: Hackernoon
Proble Formulation: Two-Phase Tuning
- The paper discusses the problem formulation of two-phase tuning.
- The objective is to minimize energy consumption and satisfy latency SLOs by finding optimal hardware configurations.
- A two-phase hardware tuning framework is proposed, where CPU tuning is done separately from tuning other hardware components.
- The optimization problem is formulated as a Bayesian Optimization problem to handle the variance and adaptively balance exploration and exploitation.
Read Full Article
14 Likes
Hackernoon
308

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Predictor Analysis
- This paper presents PolyThrottle, an energy-efficient neural network inference system for edge devices.
- The paper focuses on predictor analysis, specifically examining how the predictor schedules fine-tuning requests based on varying latency service level objectives (SLOs).
- Under stringent latency conditions, the predictor decides not to schedule fine-tuning requests to adhere to the SLOs.
- However, when the latency SLO is more relaxed, the predictor determines it is feasible to schedule fine-tuning requests.
Read Full Article
18 Likes
Hackernoon
226

Image Credit: Hackernoon
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices: Architecture Overview
- PolyThrottle is a system designed to optimize the tradeoff between latency, batch size, and energy for neural network inference on edge devices.
- PolyThrottle consists of two key components: an optimization framework that finds optimal hardware configurations for a given model under predetermined SLOs, and a performance predictor and scheduler that dynamically schedules fine-tuning requests.
- The optimization procedure of PolyThrottle automatically finds the best CPU frequency, GPU frequency, memory frequency, and recommended batch size for inference requests to minimize per-query energy consumption.
- PolyThrottle adjusts the hardware configuration offline before deployment and only performs online adjustments to accommodate fine-tuning workloads, as the latency SLO for a specific workload does not change frequently.
Read Full Article
13 Likes
Medium
281

Image Credit: Medium
The AI landscape simplified
- AI (Artificial Intelligence) provides machines with the ability to mimic human intelligence, including understanding human language, recognizing patterns, and problem-solving.
- AI has various subfields like NLP, computer vision, robotics, and machine learning.
- Machine learning trains algorithms with data to make predictions, while deep learning, a subset of machine learning, uses neural networks to handle messy data and mimic the human brain structure.
Read Full Article
16 Likes
Medium
381

Image Credit: Medium
Understanding What Is The Perceptron Trick And How It Works?
- The Perceptron Trick is a technique used to adjust the weights of a perceptron algorithm in a supervised learning scenario.
- It aims to minimize errors in classification tasks by updating the weights iteratively based on misclassified instances.
- The Perceptron Trick involves adjusting the weights of a perceptron to reduce classification errors through a step-by-step process.
- Despite its limitations, the Perceptron Trick finds applications in various domains such as binary classification, pattern recognition, and natural language processing.
Read Full Article
22 Likes
Medium
154

Image Credit: Medium
KCL Leverages Topos Theory to Decode Transformer Architectures
- A research team from King’s College London employs topos theory to explore the transformer architecture and its expressive capabilities.
- The paper establishes a categorical perspective on the disparities between traditional neural networks and transformers.
- Transformers are shown to inhabit a topos, while ReLU networks fall within a pretopos.
- The insights derived from this research have actionable implications for constructing neural network architectures mirroring the characteristics of transformers.
Read Full Article
9 Likes
For uninterrupted reading, download the app